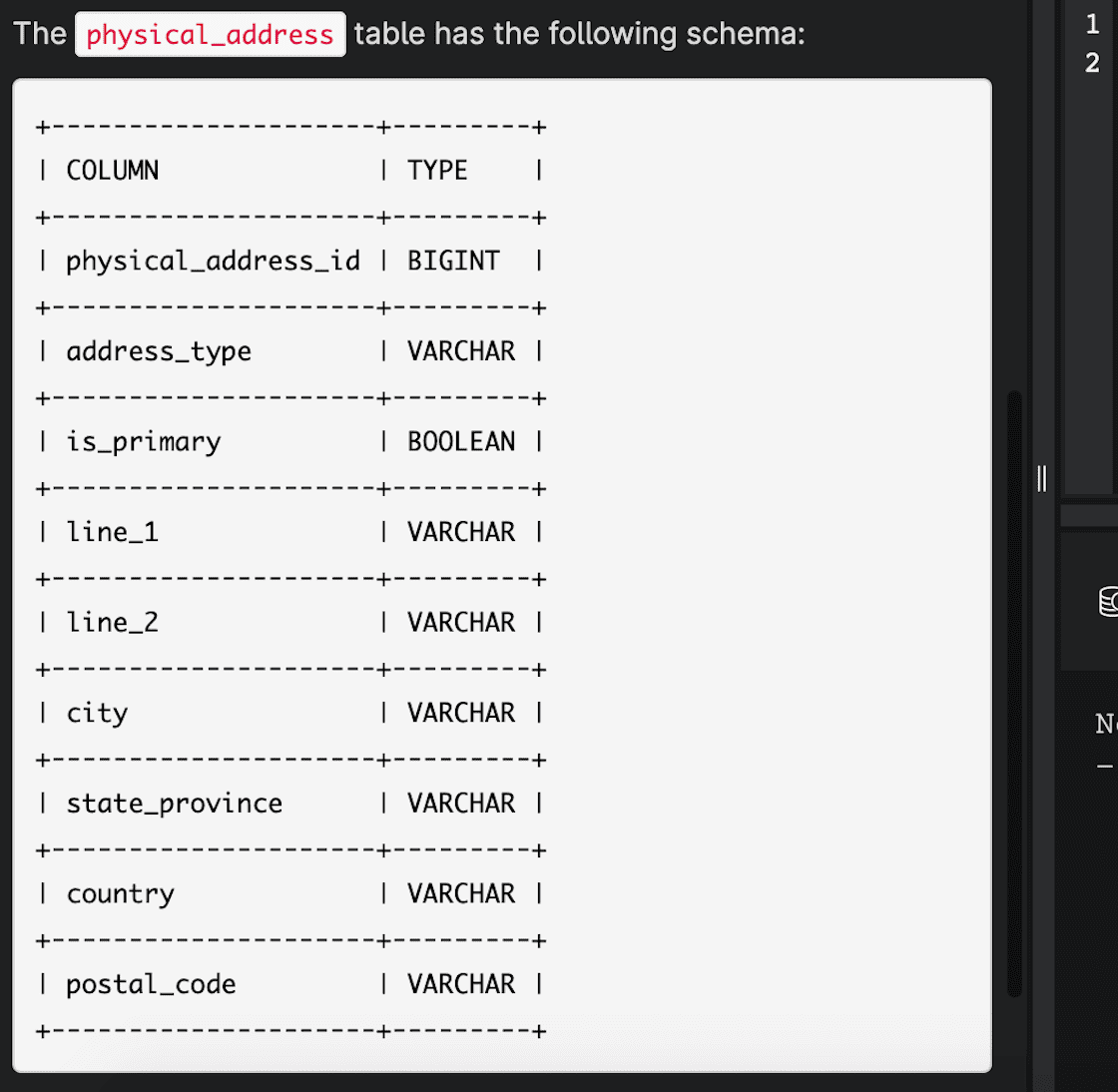
个人用笔记,因为太长了所以分成了两份.
上一回.
Notes
Note:sql的常用数据格式
| Syntax | Description |
|---|---|
| Bigint: | -1* 10(18) ~ 1* 10(18) \(<——Big Int 10^18) |
| BLOB: | Binary Large OBject 2(64) -1 \(<——最大数字2^64 - 1) |
| Boolean: | True or False |
| CHAR(500): | 500 \(500个字符) |
| Date/DateTime/Time: | ‘2020-07-25 15:25:25.666’ YYYY-MM-DD HH:MM:SS.SSS |
| Decimal: | 123.456 |
| Double: | 1* 10(-308) ~ 1 * 10(308) / -1 * 10(308) ~ -1 * 10(-308) |
| Float: | 1* 10(-38) ~ 1 * 10(38) / -1 * 10(38) ~ -1 * 10(-38) |
| INT/Integer: | 0 ~ 65535 |
| String: | length <= 4000 |
| Text: | length> 4000 \(mySql and sqlite) |
| CLOB: | Char Large Object length > 4000 |
| VARCHAR(500): | real length <= 500 \(不管多少长度都给500) |
| Real: | approximation of a real number |
注:sql中首先生成table,table中是数据格式,然后在import数据到table中.
可以在table中用双击的方式来更改格式.
Links
- The Best Medium-Hard Data Analyst SQL Interview Questions
- Select Star SQL
- Leetcode
- LinkedIn Study
- Windowfunctions
- Hacker rank
- W3schools
- Codecademy
- Sqlzoo
- Sqlbolt
- Interview query
Examples
Pivot the table in sql
Categories triangle
Write a query identifying the type of each record in the TRIANGLES table using its three side lengths. Output one of the following statements for each record in the table:
Equilateral: It’s a triangle with sides of equal length.
Isosceles: It’s a triangle with sides of equal length.
Scalene: It’s a triangle with sides of differing lengths.
Not A Triangle: The given values of A, B, and C don’t form a triangle.
Input Format
The TRIANGLES table is described as follows:
Each row in the table denotes the lengths of each of a triangle’s three sides.
Sample Input:
Sample Output
Isosceles
Equilateral
Scalene
Not A Triangle
1 | SELECT CASE |
这道题虽然是简单的,但才发现可以直接写A + B > C.
Distince
Consider P1(a,b) and P2(c,d) to be two points on a 2D plane.
a happens to equal the minimum value in Northern Latitude (LAT_N in STATION).
b happens to equal the minimum value in Western Longitude (LONG_W in STATION).
c happens to equal the maximum value in Northern Latitude (LAT_N in STATION).
d happens to equal the maximum value in Western Longitude (LONG_W in STATION).
Query the Manhattan Distance between points P1 and P2 and round it to a scale of 4 decimal places.
1 | SELECT ROUND( MAX(lat_n)-MIN(lat_n) + MAX(long_w)-MIN(long_w), 4) FROM Station; |
这道题代码也很简单,但记得decimal的问题用round来取位数.
Two minimum
Write a query to retrieve two minimum and maximum salaries from the EmployeePosition table.
To retrieve two minimum salaries, you can write a query as below:
1 | SELECT DISTINCT Salary FROM EmployeePosition E1 |
To retrieve two maximum salaries, you can write a query as below:
1 | SELECT DISTINCT Salary FROM EmployeePosition E1 |
Odd records
Write a query to calculate the even and odd records from a table.
To retrieve the even records from a table, you have to use the MOD() function as follows:
1 | SELECT EmpID |
Similarly, to retrieve the odd records from a table, you can write a query as follows:
1 | SELECT EmpID |
Nth highest
Write a query to find the Nth highest salary from the table without using TOP/limit keyword.
1 | SELECT Salary |
Rank Scores
Write an SQL query to rank the scores. The ranking should be calculated according to the following rules:
The scores should be ranked from the highest to the lowest.
If there is a tie between two scores, both should have the same ranking.
After a tie, the next ranking number should be the next consecutive integer value. In other words, there should be no holes between ranks.
Return the result table ordered by score in descending order.
DENSE_RANK.
我觉得这个function可以按两种column来排列,先PARTITION BY再ORDER BY,如果只排一种,像这道题一样按score来排,只用order by就make sense了.
1 | select score, |
Employees Earning More Than Their Managers
| Column Name | Type |
|---|---|
| id | int |
| name | varchar |
| salary | int |
| managerId | int |
id is the primary key column for this table.
Each row of this table indicates the ID of an employee, their name, salary, and the ID of their manager.
Write an SQL query to find the employees who earn more than their managers.
1 | select e.name as Employee from Employee as e |
俺写的soluntion贼慢…
1 | select E1.Name |
会快一些,left join不行啊.
Customers Who Never Order
Table: Customers
| Column Name | Type |
|---|---|
| id | int |
| name | varchar |
id is the primary key column for this table.
Each row of this table indicates the ID and name of a customer.
Table: Orders
| Column Name | Type |
|---|---|
| id | int |
| customerId | int |
id is the primary key column for this table.
customerId is a foreign key of the ID from the Customers table.
Each row of this table indicates the ID of an order and the ID of the customer who ordered it.
Write an SQL query to report all customers who never order anything.
1 | SELECT A.Name as Customers from Customers A |
Department Highest Salary
Table: Employee
| Column Name | Type |
|---|---|
| id | int |
| name | varchar |
| salary | int |
| departmentId | int |
id is the primary key column for this table.
departmentId is a foreign key of the ID from the Department table.
Each row of this table indicates the ID, name, and salary of an employee. It also contains the ID of their department.
Table: Department
| Column Name | Type |
|---|---|
| id | int |
| name | varchar |
id is the primary key column for this table.
Each row of this table indicates the ID of a department and its name.
Write an SQL query to find employees who have the highest salary in each of the departments.
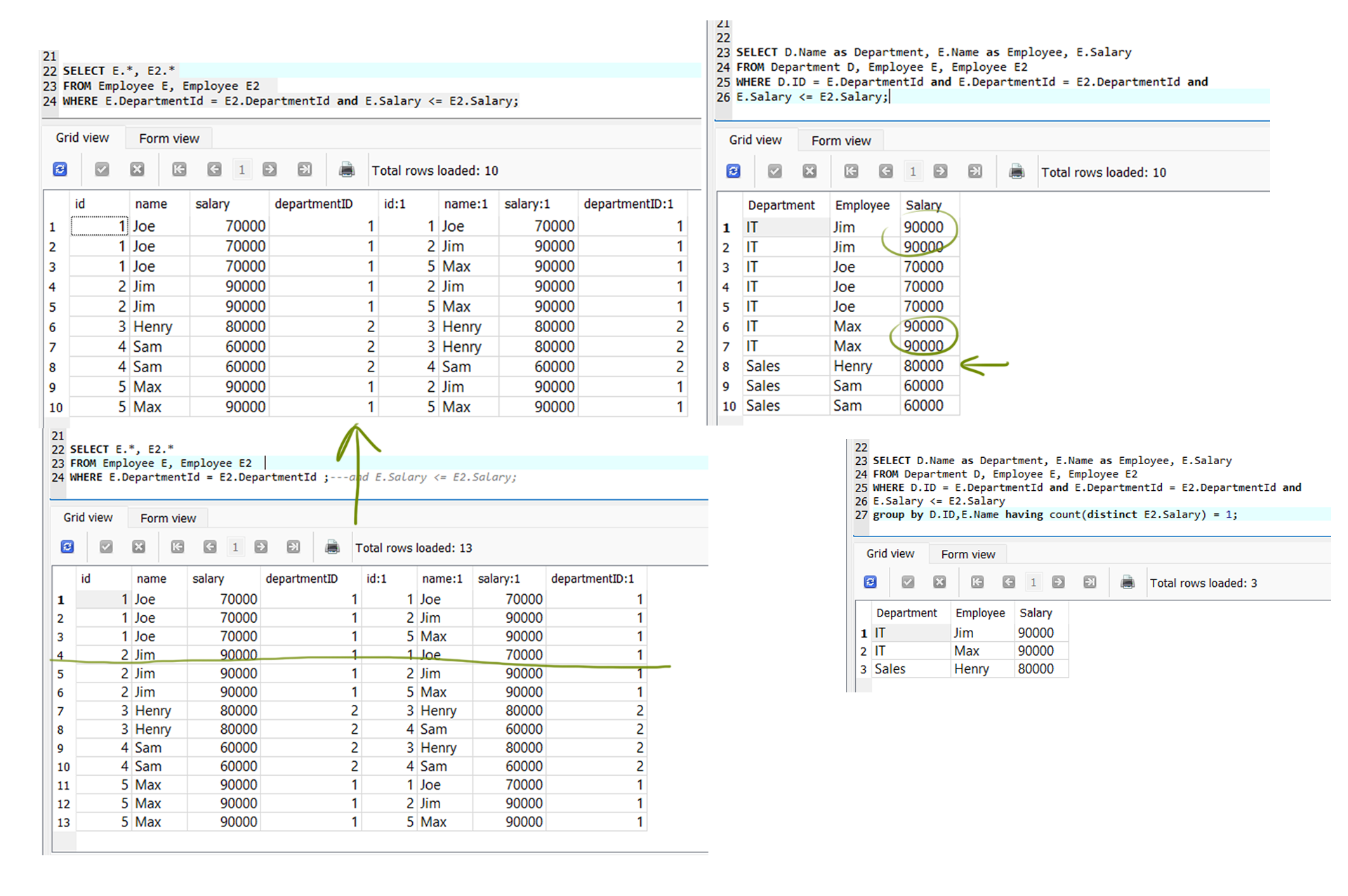
1 | SELECT D.Name as Department, E.Name as Employee, E.Salary |
Retrieve duplicate
Write a query to retrieve duplicate records from a table.
1 | SELECT EmpID, EmpFname, Department ,COUNT(*) |
Consecutive Numbers
Write an SQL query to find all numbers that appear at least three times consecutively.
Return the result table in any order.
Same department
Write a query to retrieve the list of employees working in the same department.
1 | Select DISTINCT E.EmpID, E.EmpFname, E.Department |
3rd highest
Write a query to find the third-highest salary from the EmpPosition table.
1 | SELECT TOP 1 salary |
这里插入面试时的sql题:
LAG
When does lag function useful?
What is the difference between select unique and select distinct?
SELECT UNIQUE is old syntax supported by Oracle’s flavor of SQL. It is synonymous with SELECT DISTINCT.
Use SELECT DISTINCT because this is standard SQL, and SELECT UNIQUE is non-standard, and in database brands other than Oracle, SELECT UNIQUE may not be recognized at all.
drop, delete and truncate
What is the difference between drop, delete and truncate?
When are count(*) and count distinct equal?
The COUNT(*) function counts the total rows in the table, including the NULL values.
COUNT DISTINCT does not count NULL as a distinct value.
How do you dedup rows?
Employee Salaries
Given a employees and departments table, select the top 3 departments with at least ten employees and rank them according to the percentage of their employees making over 100K in salary.
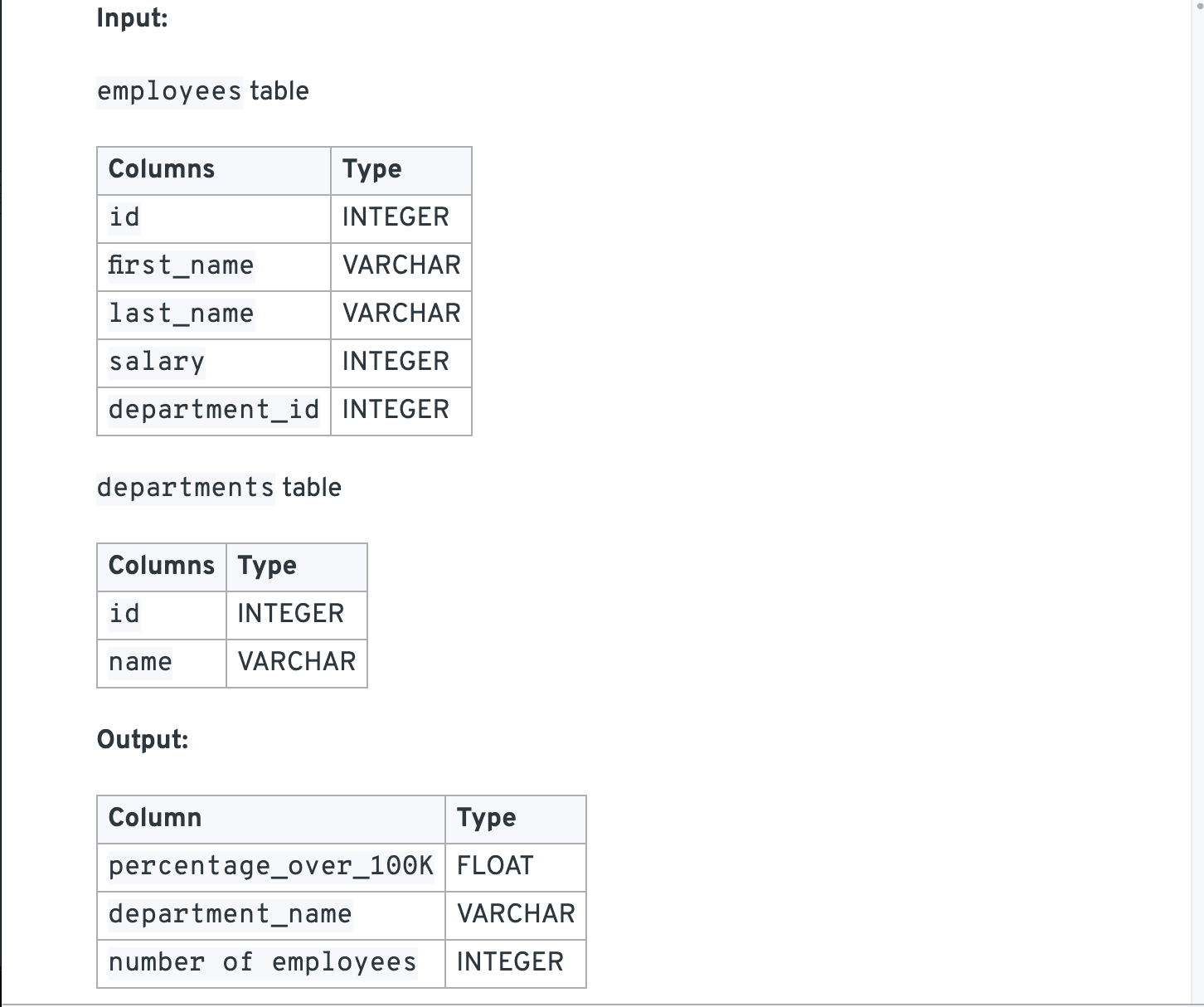
1 | -- join |
A CASE WHEN clause then allows us to differentiate when a employee makes over 100K. We can do this by running a SUM only when the employee is making over 100K. If the employee makes over 100K, then we mark the employee as a 1, otherwise we mark them as a 0.
1 | SELECT SUM(CASE WHEN |
注:Order 1的意思,
…is known as an “Ordinal” - the number stands for the column based on the number of columns defined in the SELECT clause.
ATM Robbery
There was a robbery from the ATM at the bank where you work. Some unauthorized withdrawals were made, and you need to help your bank find out more about those withdrawals.
However, the only information you have is that there was more than 1 withdrawal, they were all performed in 10-second gaps, and no legitimate transactions were performed in between two fraudulent withdrawals.
We’re given a table of bank transactions with three columns, user_id, a deposit or withdrawal value transaction_value, and created_at time for each transaction.
Write a query to retrieve all user IDs in ascending order whose transactions have exactly a 10-second gap from one another.

这道题的答案是不是过于困难了.
Since we need to identify users making transactions that occur exactly ten seconds apart, it’s useful to first order the transactions by created_at.
We need to match each timestamp to the next and previous row. We can do this by creating 2 new columns, one with the next row’s timestamps and another with the previous row’s timestamps.
Functions that perform calculations related to the current row are called window functions. The window functions, LEAD() or LAG() do exactly as explained above – LEAD() creates a new column with the next row’s timestamps, and LAG() does so for the previous row. Window functions require certain inputs, such as a partition column or an order column.
Since we care most about the time a transaction was made, we should make a table with information about time differences between transactions, and integrate it into the query using a WITH statement.
We need both of the users that made transactions with a 10 second gap. So a single window function may not be sufficient here.
In order to get the relevant user IDs, we need to get the difference between each sequential timestamp.
To do this, we use the window functions, LAG() & LEAD(). These functions create a copy of the desired column but offset it by a certain number of rows. In this case, we use the default of 1. LAG() offsets to the previous row, LEAD() offsets to the next row.
Next, we can use the OVER() clause to order by created_date in our selection. ORDER BY specifies the ordering of the rows within each partition, for the window function to apply.
The LAG() and LEAD() window functions on the created_at column get the previous & next row’s timestamp in a new column. Since we are considering the entire dataset, there is no need to consider different groups and we thereby do not need to use a PARTITION BY clause. The values have to be ordered by created_at so that the values are sequential.
We make our table with LEAD and LAG columns added as follows:
1 | with bank_transactions_lead_lag as ( |
Next we calculate the time differences to check if there is 10 second gap between transactions. We get the absolute difference in seconds, so that it’s easier to filter in the next step.
1 | , bank_transactions_time_diff as ( |
We then select the unique ordered user IDs that have a 10 second gap.
1 | SELECT DISTINCT user_id |
Putting it all together:
1 | with lead_lag as ( |
2nd Highest Salary
Write a SQL query to select the 2nd highest salary in the engineering department. If more than one person shares the highest salary, the query should select the next highest salary.
First, we need the name of the department to be associated with each employee in the employees table, to understand which department each employee is a part of.
The “department_id” field in the employees table is associated with the “id” field in the departments table. We call the “department_id” a foreign key because it is a column that references the primary key of another table, which in this case is the “id” field in the departments table.
Based on this common field, we can join both tables, using INNER JOIN, to associate the name of the department name to the employees that are a part of those departments.
1 | SELECT salary |
For our joined table, we need to filter our employees table to those employees in the engineering department.
In SQL, you should use the WHERE clause, which is used to specify a condition while fetching the data, to filter the records and fetch only the necessary records.
To filter our joined table to only include those employees that are a part of the engineering department, we would run:
1 | SELECT salary |
We need to sort the salaries from highest to lowest, which will allow us to observe which salary is highest, second highest, third highest, and so on.
Luckily, SQL provides a great way of sorting columns with the ORDER BY clause which, by default, sorts a column in ascending order (alphabetical order if categorical, or lowest to highest if numerical). In order to sort by descending order, we need to specify the DESC keyword after ORDER BY field.
1 | SELECT salary |
If two people share the same highest salary, the query should select the next highest salary. Therefore, we need to remove duplicate salaries.
SQL provides a great way for filtering out duplicate values using the SELECT DISTINCT clause, or GROUP BY clause on the specified field to return unique values. An example of GROUP BY to filter out duplicate salary values is as follows:
1 | SELECT salary |
Once the employees table is filtered for those employees in the engineering department, and the salaries are sorted in descending order, we need to extract the second highest salary.
In our filtered table, this value is located in the second row. SQL provides a way to limit the number of rows to return using the LIMIT clause. We can extract the highest and second highest salary from the employees table as follows:
1 | SELECT salary |
Now we should utilize subqueries, in order to further filter out the highest salary, and return the second highest. In SQL, a subquery is a SQL query within a query. An example for our query above is:
1 | SELECT salary |
Note that the subquery in FROM must have an alias (e.g. AS t). Using our knowledge of ORDER BY and LIMIT, how can we extract the second highest salary from the rows returned by the subquery above?
When the question prompts for “2nd highest” anything, many times people’s heads go straight to partition rank functions.
This problem isn’t meant to test your query optimization skills, but rather your understanding of basic SQL functions.
Solution
When the question prompts for “2nd highest” anything, many times people’s heads go straight to partition rank functions. Do not be fooled, the question asks for a singular value.
This can be done easily by first selecting all of the salaries within engineering. We’ll join on the department_id in both fields and filter where the department name is equivalent to engineering.
Now that we have all of the salaries, we can order by salary and only select the top two after grabbing all of the distinct values by grouping by the salary field. Then we can query from this CTE and reverse the order and select the top one which will then by the second highest salary.
1 | SELECT |
Alternative Solution (using OFFSET):
We can use the OFFSET clause, after LIMIT, to skip a prespecified number of rows before returning the rows. In this case, since our salaries are sorted in descending order, and we want the second highest salary, we can offset the highest salary row:
1 | SELECT salary |
以下是遇到的面试题.
悲伤的面试题
Find pair
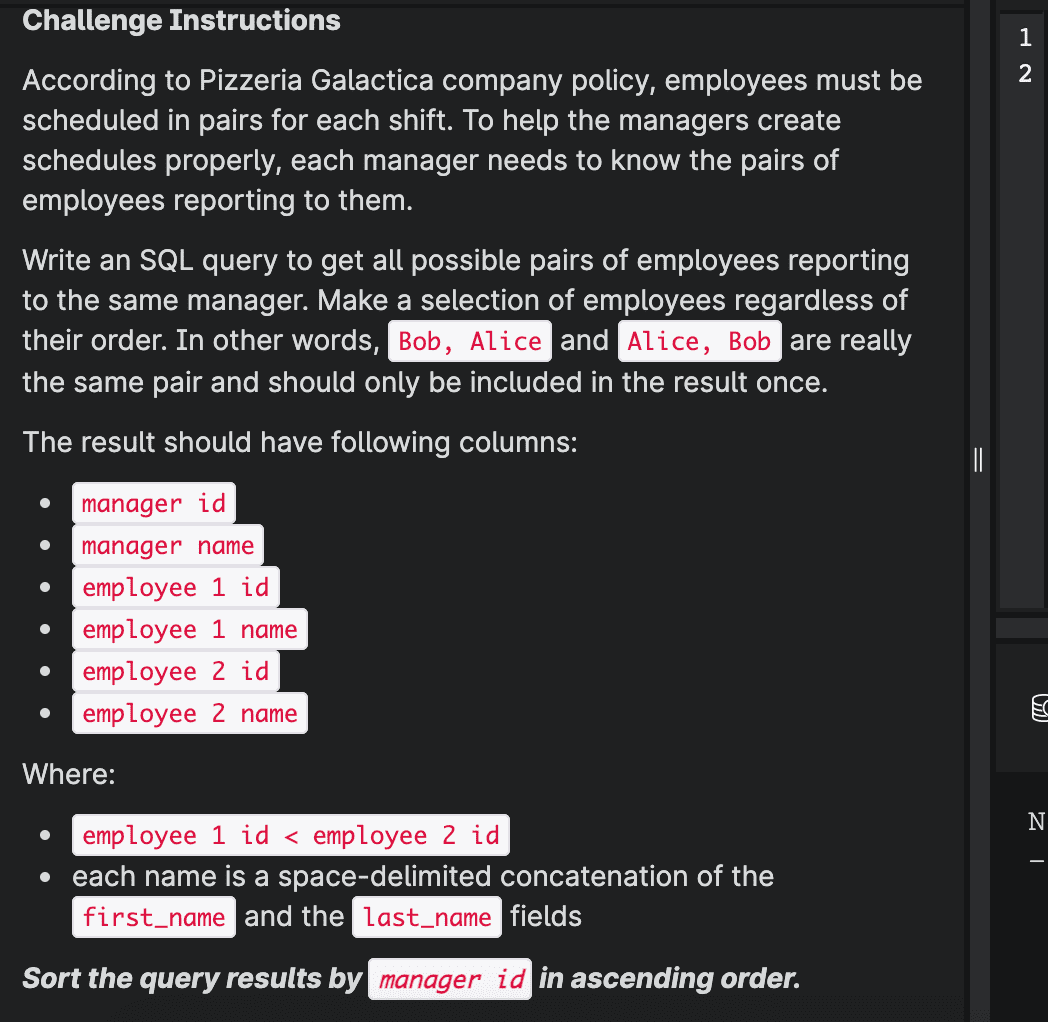
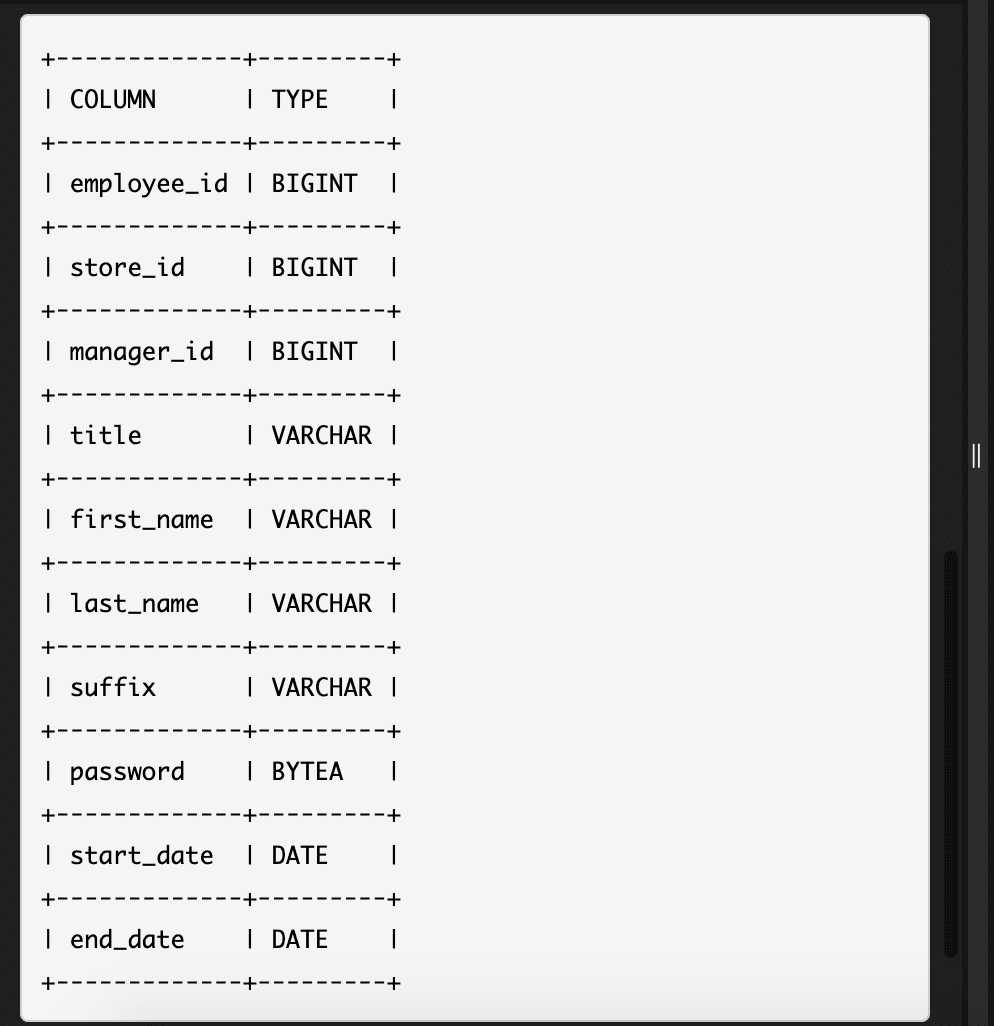
Range of address length
这道题如果能用两个query是很简单的,我现在还没学会如何并成一个query.