
个人用笔记,写的很杂(再放送).包括了初学SQL时用的sqlite,自己刷题时的mysql(dlc篇较多),最近学的Oracle中的语法.
Oracle会单独标出.
DLC篇.
Notes
关于每次每次打开SQLite studio都不记得怎么做这件事你有什么头绪吗:
db文件,是database文件.
Tab左边有open database.要导入db文件是用open database,在小窗里加入db文件的路径.
要注意看哪个database connect了哪些没有.
Tab中间有sql editor,那是写script的地方.
窗口最下面的tab是显示打开了的不同窗口的地方.
Hot key
ctrl + o -> open database
alt + e -> SQL editor
F9 -> Execute query
Comment
1 | -- comments |
基本小笔记:加入代码和数据库.
点击tool,open sql editor,在第三行的小文件load sql from file就可以加在sql的代码.
导入数据的时候,是先create table再在其table中利用import导入数据.
SQL的function分为两种,对单一value做处理的叫做elementary function(sqrt),会对多个value作处理的的叫做summary function(max).
Side Note
记得查看documentation
SQLite是大小写不敏感的,除了用string来做search的时候.
column name <= 30 characters. 只能用a-z/A-Z/0-9/_/$
doc_sql & doc_sqlite
一个table现在能有1000的columns.
如果我们要在搜索有单引号或者双引号的内容.
For example we are searching Can”a’da.
WHERE jurisdiction = ‘Can”a’’da’
两个单引号search一个单引号.
双引号不变.
但如果 WHERE jurisdiction = “Can”a’da”
两个双引号search一个双引号.
单引号不变.
Code
SELECT
Like的用法(note见sql string).
- _ which denotes one char
- % which denotes 0 or more chars
1 | SELECT Name, Continent, Population FROM Country |
在sql string tag下接string comparsion笔记.
(oracle课程中) Literal values.1 | SELECT column_name_1 ,'Hello',5,'01-Jan-15' |
Substituion variable.
1 | SELECT column_name_1 |
这是会跳出来一个框让你输入theValue的值.
Use a variable name prefixed with && to prompt the user only once.
1 | SELECT column_name_1, &&theValue |
select + as可以用于取名字或改名字.
1 | SELECT column_name_1 AS alias_name_1, -- 这时就可以改名了 |
select + format, 常用format.
1 | SELECT amount format=dollar10.2 -- 小数点前保留十位,后面保留两位 |
select + label, 给variable加label.
1 | SELECT amount label = 'usd' |
select + *, 全选.
select + calculated, calculated的作用是使用临时计算的值(在原table中没有).
1 | proc sql outobs=10; |
1 | proc sql outobs=10; |
where去掉missing(在sas中):
1 | where Salary is not missing |
在sql中可以写:
1 | where Salary ne . |
要注意细节
关于select.
我们可以使用NOT, AND, OR 来更加的区别,但注意这几个关键词有优先级.
NOT > AND > OR
所以使用NOT的时候记得用括号.(有 not in (‘A’,’B’)的语法.)
我们还可以用between.有两种写法.
1 | -- Contiunes: Between value1 and Value2 |
String也是可以连续的.C001到C004是连续的(按ascii的循序).
search多个无排序element的时候可以用in和括号.
WHERE jurisdiciton in (‘Canada’,’US’);
不等于有 <> 和 !=.
DISTINCT
select distinct 可以remove duplicate,也同时可以用来查看数据一共有的种类…
1 | SELECT Continent FROM Country; |
1 | SELECT DISTINCT column1, column2, column3 FROM Country; |
顺便一提NULL也算distinct的一种.
如果使用select distinct就会apply到所有的column,如果只要其中一个column distinct:
可以用group by.
从:
1 | ID SKU PRODUCT |
到:
1 | 1 FOO-23 Orange |
1 | SELECT * FROM [TestData] WHERE [ID] IN ( |
WHEN
condition, case和end是一定要在一起用的.
select + case when (像if else statment.)
1 | proc sql; |
这里as city_clean就是新造的column,同理可以用来categories things.
Oracle中有另一种if else:
1 | SELECT last_name, job_id, |
FROM
FROM clause + WHERE clause(WHERE + logical expression)
1 | SELECT * FROM Countries WHERE Continent = 'Europe'; |
UPDATE
用于更改数据.
1 | update table |
一次只能更新一个表.
All databases support update with subquery.
Only MySQL support update with subquery and with join statement.
1 | UPDATE Customer |
如果没有where就会把所有的都替换.
DELETE
1 | delete from table where column1=value1 [and/or] column2=value2... |
1 | DELETE FROM Customer WHERE id = 4; |
delete删除的数据后台还有保留,就是可以找回.
Note:增删改只能一个一个命令来.
AS
as create column的alias名字.注:as有时可以省略.
1 | SELECT ‘Helloworld’ AS Result; |
ORDER BY
sorting的一种方式.
1 | SELECT * FROM Country ORDER BY Name; |
Note: single quote for string, double string for most of other things(eg. identifier).
1 | SELECT Name FROM Country ORDER BY Name DESC; -- descending 从z到a的顺序 |
Example:
Query the two cities in STATION with the shortest and longest CITY names, as well as their respective lengths (i.e.: number of characters in the name). If there is more than one smallest or largest city, choose the one that comes first when ordered alphabetically.
这道题如果写两个query,我会先把city按alphabetical order给排序好,再用select min(city), length(min(city))来写.
1 | (select city, length(city) |
这是答案的代码,思路也很清晰:按length先排,再按alphabetical order排.
我试max(city)或者min(city)会跑不出来.
max(city):’Zionsville’
order by length(city) desc:’Marine On Saint Croix’
注意到了吗!!直接比较city,比较的不是按string长度,而是acsii的value(震惊).
WHERE
选择部分(row)data.
1 | SELECT Name, Continent, Region FROM Country WHERE Continent = 'Europe'; |
如果要选两个,可以用in+括号.
1 | SELECT Name, Continent, Region FROM Country WHERE Continent in ('Europe','Africa'); |
举例之选择even number of rows:
sql的除法是%.
1 | select distinct city from station |
LIMIT and OFFSET
选择部分(row)data.
1 | SELECT Name, Continent, Region |
我们也可以用limit来做offset的事.
1 | LIMIT [# of records]|[(# of start) - 1, # of records]; |
上面是给SQLite和MySQL的.
或者使用TOP.
Access, MS SQL SERVER - Microsoft – Transact-SQL -> T-SQL
Select top [# of records] | [(# of start) - 1, # of records] column1, column2 From Table
Select top [# of records] | [(# of start) - 1, # of records] * From Table
注意其他的语法可能不一样,最好查看doc.
用limit在求第二大小的数:
1 | Limit 1, 1; |
COUNT
count rows.
1 | SELECT COUNT(*) |
注意NULL不会被count进去. Count( * ) 比select * 快很多.
Example:
Find the difference between the total number of CITY entries in the table and the number of distinct CITY entries in the table.
1 | select count(city) - count(distinct city) from station; |
INSERT INTO
用code码的方式add data.
1 | insert into Table(column1,...) values (value1, ...) |
当用第二种方式的时候,可以用NULL来空去没有值的column.
Primary key不能为空(null).
1 | INSERT INTO Customer (name, city, state, zip) |
1 | INSERT INTO test VALUES ( 1, 'This', 'Right here!' ); |
我们也可以用subquery来insert.
不过注意,如果将一个表格复制给它本身,也就是将数据翻倍.很可能出现primary key也重复而报错的情况.
所以要做改动.
1 | insert into bond_price |
INSERT INTO(Oracle)
- List the columns that will receive values
- List the corresponding values in the VALUES clause
- Enclose character and date values in single quotations
1 | INSERT INTO departments(department_id, department_name, manager_id, location_id) |
Inserting nulls
Implicit method: Omit the columns from the column list(会默认null)
1 | INSERT INTO departments (department_id,department_name) |
Explicit method: Specify NULL in the VALUES list
1 | INSERT INTO departments(department_id, department_name, manager_id, location_id) |
Copy rows from another table.
1 | INSERT INTO sales_reps(id, lname, salary, comm) |
CREATE TABLE
在SQLite studio中,得先建database,database->add a database,然后创造的table就在database之中了.
新建table后,在tools,import中选择其table和导入文件.
1 | CREATE TABLE test ( |
这里的data type,有 NULL, INTEGER, REAL(像c里的float), TEXT(string value), BLOB(stored exactly as it was input).
SQLite没有Boolean,可以手动用0(false)和1(true).
(在SQL-续里有更详细的笔记).
1 | CREATE TABLE test ( |
Note: we can have more NULL while using UNIQUE(depends on different system)
格式是 column_name + data_type + PRIMARY KEY/ NOT NULL/ NOT NULL UNIQUE.
specify the column list of the table. Each column has a name, data type, and the column constraint. SQLite supports PRIMARY KEY, UNIQUE, NOT NULL, and CHECK.
specify the table constraints such as PRIMARY KEY, FOREIGN KEY, UNIQUE, and CHECK constraints.
1 | CREATE TABLE [IF NOT EXISTS] [schema_name].table_name ( |
在initial的时候需要加括号来define column.
中途想要把result记载下来时,
1 | create table temp_1 as |
不需要加括号,注意有as.
CREATE TABLE(Oracle)
跟sqlite不同,oracle定义table时要注明size.
For each column the following must be specified
- The column name
- The column datatype and size where applicable
- Any constraints you want applied to the column
1 | CREATE TABLE table_name |
Constraints:
- Primary key: Uniquely identifies each row with non-null value
- Foreign key: Establishes Referential Integrity between the column and a unique identifier, usually in another table, so the values in the two columns match
- Unique: The values must be unique in each row
- Not null: The column cannot contain nulls
- Check: Specifies which values are allowed
1 | CREATE TABLE departments |
Index
Index are used for improving performance in a table.
1 | CREATE INDEX idx_staff_last_name |
index on staff table
DROP TABLE
1 | CREATE TABLE test ( a TEXT, b TEXT ); --here will have a error since the table is already created |
Truncate: 跟drop table类似但不同.会把table里所有的数据删掉,table保留.
IS NULL
When search for null
1 | SELECT * FROM test WHERE a IS NULL; |
1 | DROP TABLE IF EXISTS test; |
NVL(Oracle)
一种查到了null替换值的function.
NVL(val1,val2) -> if val1 null, return val2.
NVL2(val1,val2,val3) -> if val1 null, return val2, else return val3.
1 | SELECT last_name, NVL(commission_pct, 0) AS commission_pct |
1 | SELECT last_name, salary, commission_pct, |
NULL
关于null的note:
null在计算avg和sum时不受影响.如果全部都是null的数据,min,max也会return null.
null进行加减乘除,或者大小比较也是return null.
null == null也是return null.
logic involve null(unknown)的时候:
| True | False | Both | |
|---|---|---|---|
| or | unknown or true == true | unknown or false == unknown | unknown or unknown == unknown |
| and | unknown and true == unknown | unknown and false == false | unknown and unknown == unknown |
| not | not(unknown) == unknown |
COALESCE
用来默认替换null的.
SELECT COALESCE(要查找的column_name, replace null的值);
Evaluates the arguments in order and returns the current value of the first expression that initially doesn’t evaluate to NULL.
For example, SELECT COALESCE(NULL, NULL, ‘third_value’, ‘fourth_value’); returns the third value because the third value is the first value that isn’t null.
ALTER
add a new column
1 | ALTER TABLE test ADD d TEXT; |
ID columns
this is different in different data system
1 | CREATE TABLE test ( |
Join table
(aka join table)
Each row of table has a unique key. The table’s unique key may or may not correspond with a column in the table.
Sometime unique key is hidden but the table must have one.
When a column is used as a unique key, it often called primary key (子table) .(用于identify)
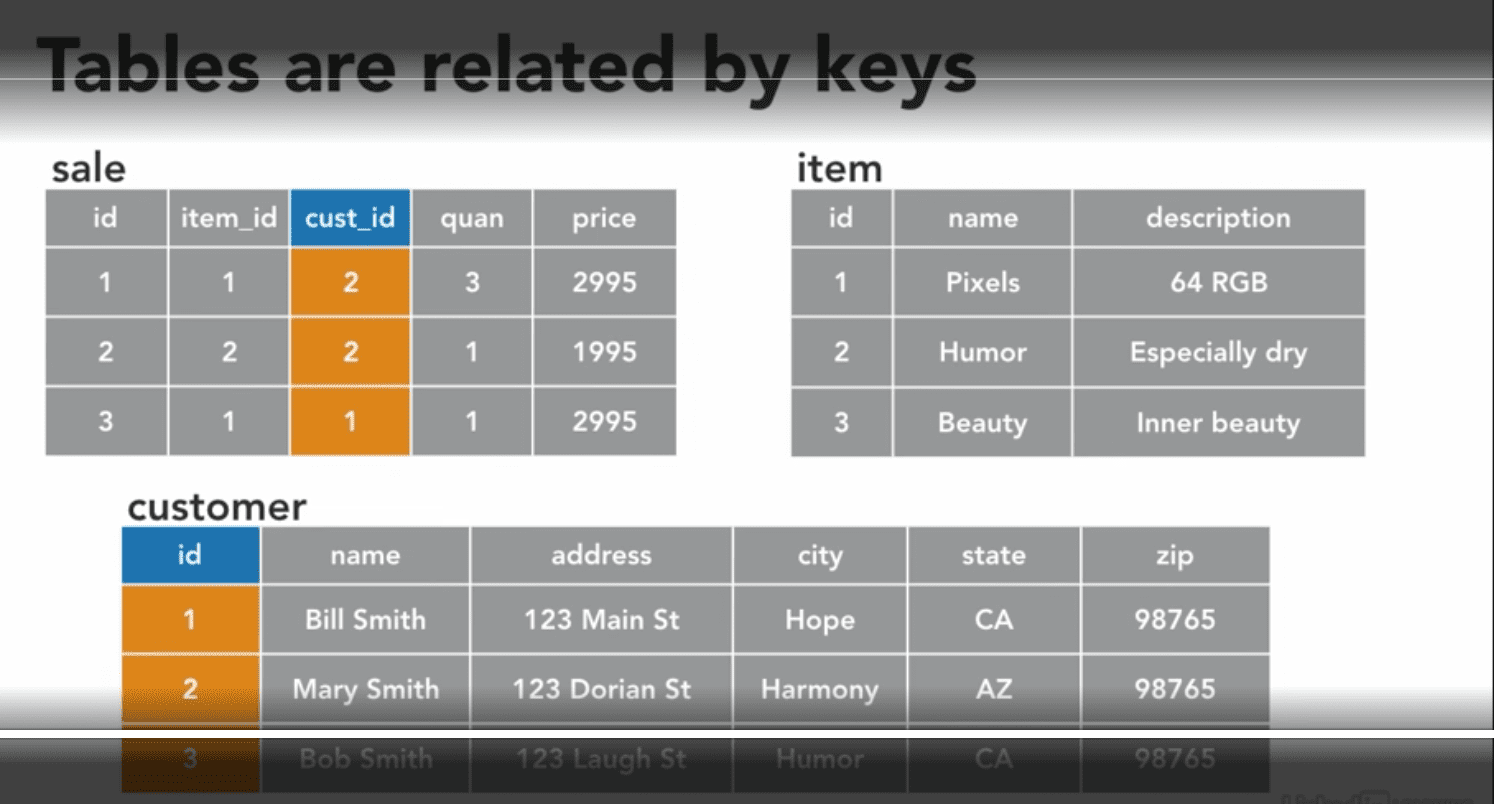
通过key来连接各个表格.这是的连接用key被称为foreign keys(主table).
如果链接的一方是primary key,自己就是foreign key.
种类:
Inner join(no null),保留两个table的共同值.
Outer join(may have null): LEFT/RIGHT/FULL join
Right and full outer join are not supported in sqlite right now 但是可以用left改写right.
Left join:
| Num | Var |
|---|---|
| 1 | A1 |
| 2 | A2 |
| 3 | A3 |
| Num | VarB |
|---|---|
| 1 | B1 |
| 2 | B2 |
| 4 | B4 |
| Num | VarA | VarB |
|---|---|---|
| 1 | A1 | B1 |
| 2 | A2 | B2 |
| 3 | A3 |
1 | SELECT a.column1, ... ,b.column1, ... |
Another inner join example:
(这样的join默认inner join)
1 | SELECT a.*, b.* |
1 | proc sql; |
If we have two keys in the right table, only have one in left table.
Join(inner + left + right) will keep two keys in right table and two copy of info in the joined table.
If we have two keys in the right table, have two in left table as well.
Join(inner + left + right) will have 4 results.
Natural Join(Oracle)
Oracle的笔记.
Joins tables based on all columns with the same name and datatype.
1 | SELECT department_id, department_name, location_id, city |
Join using(Oracle)
Oracle里有两种普通join的写法.一种是用using,还有一种是跟sqlite一样用等号.
1 | SELECT employee_id, last_name, department_id, department_name |
用等号叫做:Equijoin.
Three way join(Oracle)
1 | SELECT employee_id, last_name, department_name, city |
可以在join时同时加入condition.
1 | SELECT employee_id, last_name, department_name |
Non equijoin(Oracle)
An operator such as BETWEEN…AND can be used to display an employee’s salary grade.
1 | SELECT grade_level, salary, last_name |
Non standard joins(Oracle)
一种格式不大一样的Oracle only的join.
1 | SELECT last_name, department_name, city |
Combine two tables(right and left relationship)
Relational database, using JOIN clause
1 | CREATE TABLE left ( id INTEGER, description TEXT ); |
1 | -- (outer join, 全部join) |
1 | SELECT s.id AS sale, s.date, i.name, i.description, s.price -- 这里可以选更多的一起放到表格里来 |
Oracle中的left join算left full join:
1 | SELECT last_name, department_name |
Junction table(many to many relationship)
1 | SELECT * FROM customer; |
1 | INSERT INTO customer ( name ) VALUES ( 'Jane Smith' ); |
在oracle中有类似的Cross join: >Generates a Cartesian Product.
1 | SELECT last_name, department_name |
UNION
合并table.多个table竖着合并.
Union中会选择union前的column name作为最后的column name.
1 | SELECT column_name(s) FROM table1 |
1 | SELECT column_name(s) FROM table1 |
注:
Union 会默认remove duplicated rows,union all不会.
关于Oracle的竖着的合并:
Union和Union all 一样,注意union会自带sort:
Union all:
- Including duplicated rows
- Result is not sorted
Union:
- Removing duplicated rows
- Performs a record sort, from left to right
Intersect:
- Returns the rows that are common to both queries
- Displays names that appear in both tables, removing duplicated rows
- Performs a record sort
1 | SELECT first_name, last_name |
Minus:
- Returns the distinct rows selected by the first query not selected by the next query
- Displays employees who are not consultants, removing duplicated rows, if any
- Performs a record sort
(也就是第二个query的数据用来减第一个query.)
1 | SELECT first_name, last_name |
关于这些竖着的合并:
- All column headings come from the first query, use generic column aliases as needed
- The number of columns selected must match
- The datatype family of the columns selected must match
- The order by clause can appear only once, at the very end
- To avoid confusion, it is common practice to order by column integers
比如把order2放在最后面:
1 | SELECT first_name, last_name |
1 | SELECT employee_id, job_id, salary |
把从job_history里的数据在salary里默认为0.
1 | SELECT location_id, department_name, NULL AS city |
注意第一个query中要确认名字,空出null为city给第二个query.
而第二个query中的departent_name就不用.
Self join
Write an SQL query to fetch the list of employees with the same salary.
1 | Select distinct W.WORKER_ID, W.FIRST_NAME, W.Salary |
来自Oracle的Self join笔记: You may need to scan more than one row in a table to arrive at an answer. 例子:一个employee有id也有manager_id.要直接寻找employee的manager可以按两者的id join.
1 | SELECT e.last_name as emp, m.last_name as mgr |
Substitution variables(Oracle)
Use a variable name prefixed with & to prompt the user
1 | SELECT first_name, last_name, salary, job_id |
会跳出让输入empid的窗口.
Use a variable name prefixed with && to prompt the user only once
1 | SELECT first_name, last_name, salary, &&col4 |
SQL string
1 | -- in standard sql case |
每个system不大一样,记得查看documentation(再放送).
// in SQLite case
1 | -- string length |
1 | -- 数每一个city的名字长度,从大到小排序. |
用SUBSTRING来cut string.
What is the difference between substr and substring in SQL?
Both functions take two parameters, but substr() takes the length of the substring to be returned, while substring takes end index (excluding) for a substring.
1 | -- substring |
截取string可以用于改名.
注意:
在SQLite中没有substring只有substr.
SQLite中也没有right:从右边cut string.
如果要从右边cut string,可以用substr(‘THE STRING’, -6).
接select的string comparison:
Like和equal(=)的区别.,一个是match一组pattern,一个是完全等于.
Special character in sql.
Find all special characters in a column in SQL Server 2008.
^ (as the first character inside []) says “anything not in this range. The [] block can just contain individual characters - you just put each possible character in turn. The above is equivalent to [^aAbBcCdD….yYzZ0123456789’. If you said [^a-Z,0-9] then you’re just allowing , as another character that will not be highlighted.
关于这个capital(^)的字符,在sql里是not的意思,但在bash的笔记中是beginning的意思.
包括bash中并没有百分号(%)的使用.这个两个不同啊.
Other wildcards symbols.
MySQL和sqlite和其他也有区别,要注意(悲).
Example:
Query the list of CITY names starting with vowels (i.e., a, e, i, o, or u) from STATION. Your result cannot contain duplicates.
1 | -- mysql的答案 |
这题也可以笨一点的做,用cut string的方式来compare第一个字母.
Ending with vowels (i.e., a, e, i, o, or u):
1 | SELECT DISTINCT CITY FROM STATION WHERE RIGHT(CITY,1) IN ('a','i','e','o','u'); |
1 | -- % : a%b -> ab, aab, axbdb |
注意,这个加下划线和百分号的使用是跟like相关的.
以及并不能一起用like和in.
INSTR(Oracle)
INSTR returns the numeric position of a substring.
INSTR(column, ‘string’ , beginning position , occurrence)
- 0 is returned if the substring is not found
- The position where you want the search to start. Position 1 is the default
- Which occurrence you want searched for. Occurrence 1 is the default
1 | SELECT street_address, INSTR(street_address, ' ') |
用空格很实用.
INSTR(Oracle)
Use LPAD and RPAD to pad a column on the left or right with specified character(s) up to a specified length
Pad the salary on the left with $ up to a length of 6 characters
1 | SELECT LPAD(salary, 6, '$') |
一共6个char,左边空出来的加$.
Char data type(Oracle)
关于Orcale char的data type:
Varchar2
- used for variable-length character columns
- has a maximum length of 4000 characters
- most character data is of this type
last_name VARCHAR2(15)
Char:
- used for fixed-length character data columns
- has a maximum length of 2000 characters
- useful for country codes and other fixed-length character data
country_id CHAR(2)
My sql也有类似的varchar(没有2),和char,详情.
Oracle:
Use LIKE to perform wildcard searches through character, number, date, and timestamp data
Search conditions will be in quotes, or ticks, and can contain
- Literal values
- _ which denotes one character
- % which denotes 0 or more characters
TRIM
可以做到“remove white spaces from the right side”之类的.
1 | SELECT TRIM(' string '); -- 会remove all spaces |
TRIM(Oracle)
Oracle中的trim感觉很不一样…
TRIM the leading S from email
1 | SELECT email, TRIM(LEADING 'S' FROM email) FROM employees |
TRIM the trailing S from email
1 | SELECT email, TRIM(TRAILING 'S' FROM email) FROM employees |
TRIM BOTH the leading and training S from email
Because BOTH is the default, it can be omitted
1 | SELECT email, TRIM(BOTH 'S' FROM email) |
REPLACE
Example: Write an SQL query to print FIRST_NAME from Worker table after replacing ‘a’ with ‘A’.
1 | Select REPLACE(FIRST_NAME, 'a', 'A') from Worker; |
SQLite也能做,好强.
CONCAT
用于合并两个column的value,append string那样的感觉.
Example: Write an SQL query to print the FIRST_NAME and LAST_NAME from Worker table into a single column COMPLETE_NAME. A space char should separate them.
1 | Select CONCAT(FIRST_NAME, ' ', LAST_NAME) AS 'COMPLETE_NAME' from Worker; |
SQLite并不支持concat.
但是可以使用|| <-真是淳朴的链接方式!
1 | Select FIRST_NAME || ' ' || LAST_NAME AS 'COMPLETE_NAME' from Worker; |
(同时mysql不支持||,悲)
UPPER and LOWER
they convert ASCII characters
1 | SELECT 'StRiNg' = 'string'; -- this returns false,大小写matters |
在oracle中还有一种格式function:
Change the output character data to capitalized initials
1 | SELECT email, INITCAP(email) |
SQL number
again:每个system都不一样
fundamental numeric types: real & integer
integer types:


real number sacrifice accuracy for scale.
Oracle的nuber:
Contain variable-length number data up to 38 digits long
Number data could be
- Integer data created with a Precision
- Floating point data created with Precision and Scale.
Precision - the total number of digits:
employee_id NUMBER(6)
Scale specifies how many digits are on the right of the decimal.
gross_pay NUMBER(9,2) – 9 is Precision and 2 is scale
TYPEOF
1 | SELECT TYPEOF( 1 + 1 ); -- integer |
CAST
cast用于转换数据类型.cast(express as datatype)
string转int好助手.
//integer的result always be integer
1 | SELECT 1 / 2; -- result is 0 |
cast可以用来拼接字符串.先把数字转换成char,在用||拼接.可以拼成百分号的数字.
1 | Cast(round((high-low)/(open+close) * 2,2) * 100 as varchar) || '%' as vol -- (别名) |
ROUND
四舍五入函数.
round(expression, precision精度)
精度可以是负数,保留到百位.
1 | SELECT 2.55555; |
Oracle:
Trunc: Rounds a value down to a specified decimal
Mod: Returns the remainder of division
Ceil: Returns the smallest integer greater than a number
Floor: Returns the largest integer less than a number
1 | SELECT ROUND(187.8575,2) |
Nested and Repeated Data

自带class的感觉.
Nested columns have type STRUCT (or type RECORD). This is reflected in the table schema below.
Recall that we refer to the structure of a table as its schema. If you need to review how to interpret table schema, feel free to check out this lesson from the Intro to SQL micro-course.
1 | # Print information on all the columns in the table |
SchemaField(‘author’, ‘RECORD’, ‘NULLABLE’, None, (SchemaField(‘name’, ‘STRING’, ‘NULLABLE’, None, (), None), SchemaField(‘email’, ‘STRING’, ‘NULLABLE’, None, (), None), SchemaField(‘time_sec’, ‘INTEGER’, ‘NULLABLE’, None, (), None), SchemaField(‘tz_offset’, ‘INTEGER’, ‘NULLABLE’, None, (), None), SchemaField(‘date’, ‘TIMESTAMP’, ‘NULLABLE’, None, (), None)), None),
比如说在这个名为committer的column里面,有很多种项目.
如果要access name这一栏,用committer.name.

自带array的感觉.
When querying repeated data, we need to put the name of the column containing the repeated data inside an UNNEST() function.

要选择repeated data的时候:
1 | FROM `bigquery-public-data.github_repos.languages`, |
repeated column会分开来select.
SQL date and time
SQL store date and time in UTC
//for SQLite
1 | SELECT DATETIME('now'); -- in UTC -> ‘2020-11-24 15:07:13’ |
这里是后期订正:
在sqlite中遇到了’D/M/YYYY’格式的string,想要转换成timestamp.
用了很笨的方法:
先把最后的year给cut出来,
用负值的substr,substr(‘’D/M/YYYY’’, -4).
把’D/M’给cut出来:
Remove the last character in a string in T-SQL?
再把D和M分开:
SQLite split string.
最后用integer value合并一个timestamp:
select date(my_year ||’-01-01’,’+’||(my_month-1)||’ month’,’+’||(my_day-1)||’ day’);
SQLite: how to create a date from integer year and month components?
想知道更聪明的方法…
关于sql还有一个截取时间的办法.
1 | Strftime(format, timestring[,modifiers]) |
| format | explanation |
|---|---|
| %Y | year with century(yyyy) |
| %m | month(01-12) |
| %d | day of the month(1-31) |
| %H | hour on 24-hour clock(00-23) |
| %M | minute(00-59) |
| %S | second(00-59) |
| timestring | explanation |
|---|---|
| now | now is a literal used to return the current date |
| YYYY-MM-DD | date value formatted as ‘YYYY-MM-DD’ |
| HH:MM:SS.SSS | HH:MM:SS.SSS |
对于timestamp来说,可以用 datepart() function来分别时间和日期.
1 | select distinct datepart(timestamp) as date format=date --通过format转换成看得懂的格式 |
SQL date and time(Oracle)
TO_CHAR
TO_CHAR(date, ‘format model’)
Converts dates from the default DD-MON-RR format to a more readable format based on the format model you provide
- Must be enclosed in single quotes
- May be caSe sEnsiTive
- Use fm to remove extra spaces and/or leading zeros
| Element | Description |
|---|---|
| YYYY | Four digit year |
| YEAR | Year spelled out - case sensitive |
| MONTH | Month spelled out - case sensitive |
| MON | Three letter month - case sensitive |
| MM | Two digital month |
| DAY | Day of the week spelled out - case sensitive |
| DY | Three letter day - case sensitive |
| DD | Two digit day of the month - case sensitive |
| AM or PM | Meridian Indicator |
| A.M. or P.M. | Meridian Indicator with periods |
| HH or HH12 or HH24 | Hour of day 12-11 or 12-11 or 00-23 |
| MI | Minutes 0-59 |
| SS | Seconds 0-59 |
| SSSSS | Seconds since midnight 00000-86399 |
1 | SELECT TO_CHAR(start_date, ‘DD Month, yyyy’) AS start_date |
dual is the dummy table.
TO_CHAR can also use in number.
| Element | Description |
|---|---|
| 9 | Represents one digit |
| 0 | Forces a zero to be displayed |
| $ | Displays a floating dollar sign |
| . | Displays a decimal point |
| , | Displays a comma |
| L | Floating local currency symbol |
| G | Local group separator |
| D | Local decimal symbol |
1 | SELECT TO_CHAR(salary, '$999,999.99') AS salary |
会得到$13,000.00格式的数字.
类似还有TO_DATE的function.
Converts characters into dates using the same available format elements as TO_CHAR
1 | SELECT last_name, salary, hire_date |
Aggregate(聚合函数)
1 | -- here we count all countries |
1 | -- here we count all countries in different region |
GROUP BY:用于分组.
The GROUP BY clause allows you to apply the summary functions to a group of observations (the same as CLASS statement in PROC MEANS), you only need it when you apply summary functions.
如有以下的数据:
| gender | height |
|---|---|
| male | 60 |
| female | 70 |
我们通过group by gender来求不同gender的height mean.
If you specify a GROUP BY clause in a query that does not contain a summary
function, your clause is changed to an ORDER BY clause, and a message to
that effect is written to the SAS log.
1 | select cty, mean(amount) as Avg_fraud_dollar from disk.txn_data_v9 where fraud='Yes' |
1 | SELECT column1,column2,columnN, |
如果用group by搜寻max,每一组只会返回一个数据,在同时出现两个max的情况下,我们可以先找出每组的最高,再用这个数据去搜索拥有最高的人.
select和group by的列得对应.如果run出来有问题…可以试试在group by里增加全select的列.
寻找第二大的数:
1 | -- 用order by |
或者
1 | SELECT name, MAX(salary) AS salary |
Write an SQL query to determine the nth (say n=5) highest salary from a table.
Ans.
The following MySQL query returns the nth highest salary:
1 | SELECT Salary FROM Worker ORDER BY Salary DESC LIMIT n-1,1; |
The following SQL Server query returns the nth highest salary:
1 | SELECT TOP 1 Salary |
WITH AS
On its own, AS is a convenient way to clean up the data returned by your query. It’s even more powerful when combined with WITH in what’s called a “common table expression”.
A common table expression (or CTE) is a temporary table that you return within your query. CTEs are helpful for splitting your queries into readable chunks, and you can write queries against them.
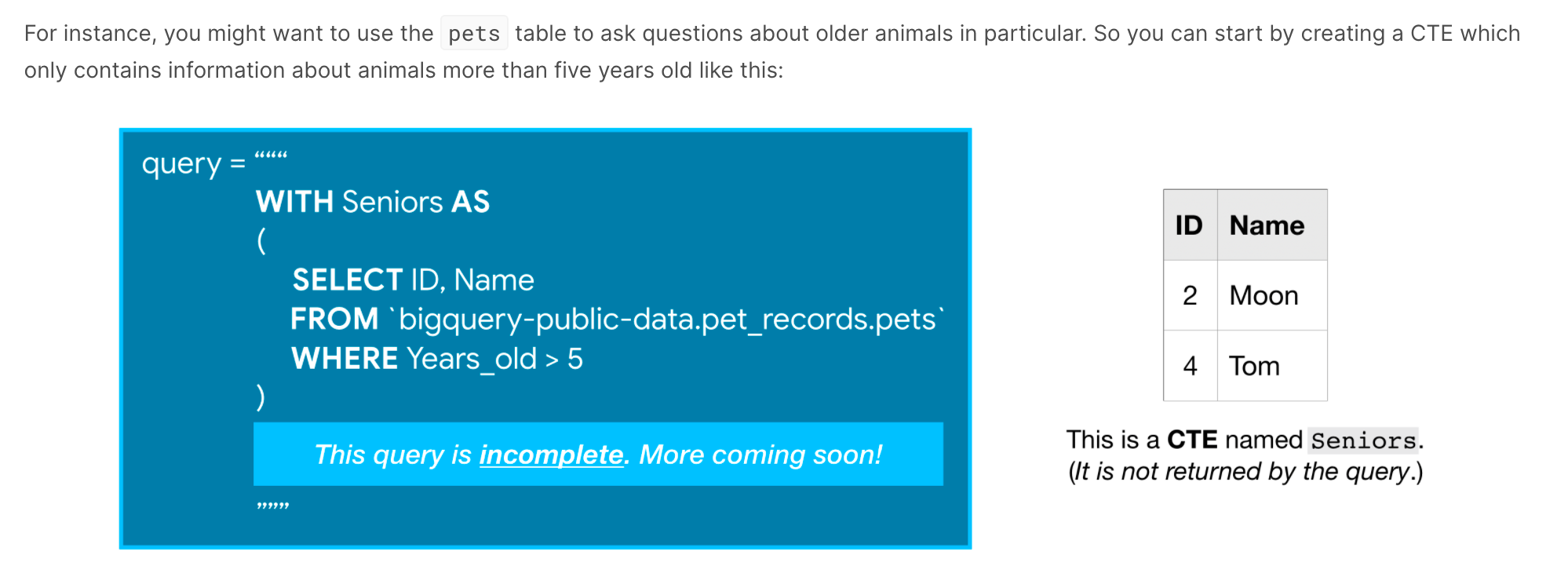
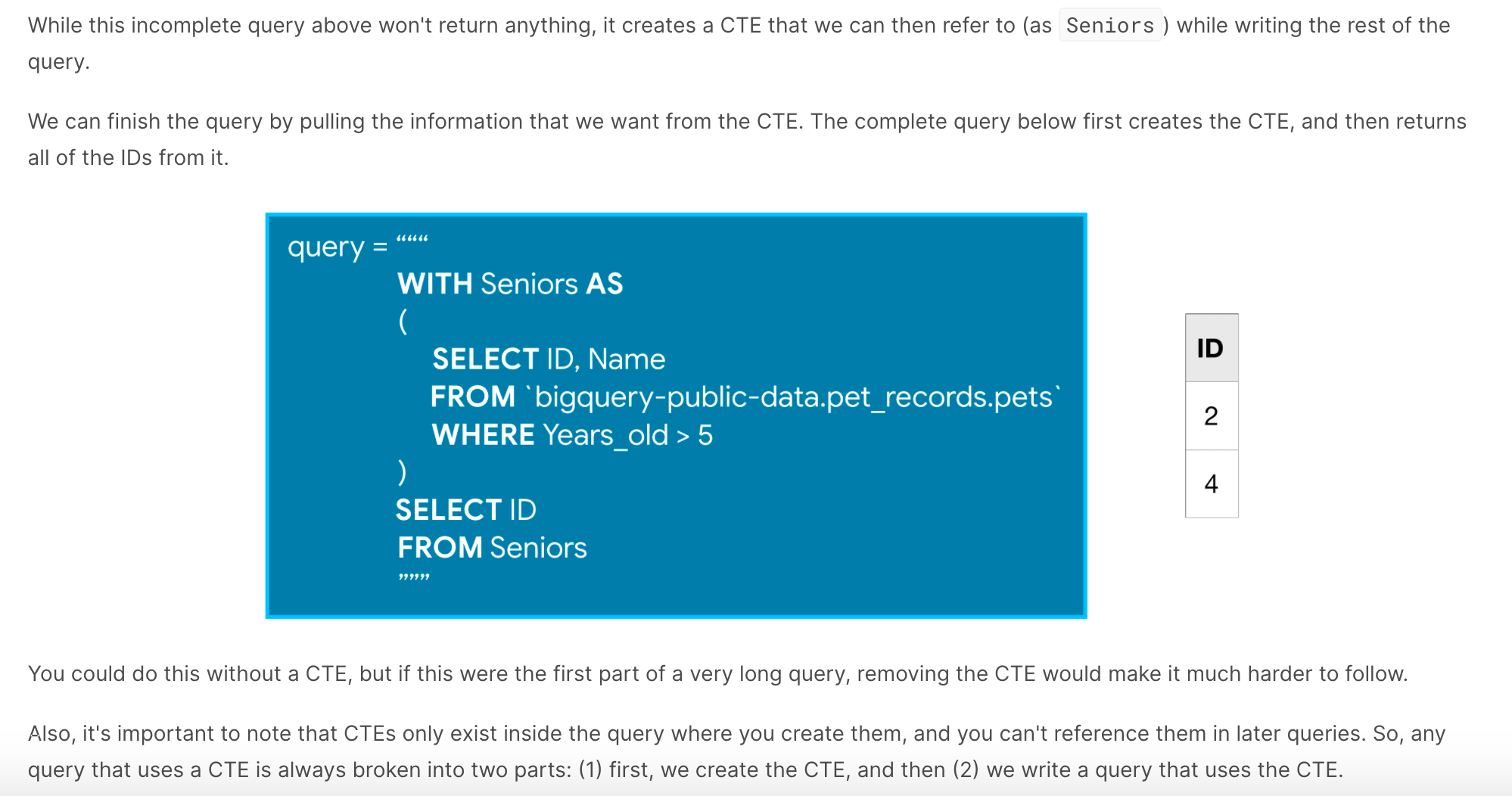
Analytic function
This is a good way to do rolling time aggregation.
1 | WITH trips_by_day AS |
| trip_date | num_trips | cumulative_trips | |
|---|---|---|---|
| 0 | 2015-01-01 | 181 | 181 |
| 1 | 2015-01-02 | 428 | 609 |
| 2 | 2015-01-03 | 283 | 892 |
| 3 | 2015-01-04 | 206 | 1098 |
| 4 | 2015-01-05 | 1186 | 2284 |
具体见kaggle教程.
- Analytic aggregate functions
As you might recall, AVG() (from the example above) is an aggregate function. The OVER clause is what ensures that it’s treated as an analytic (aggregate) function. Aggregate functions take all of the values within the window as input and return a single value.
MIN() (or MAX()) - Returns the minimum (or maximum) of input values
AVG() (or SUM()) - Returns the average (or sum) of input values
COUNT() - Returns the number of rows in the input
- Analytic navigation functions
Navigation functions assign a value based on the value in a (usually) different row than the current row.
FIRST_VALUE() (or LAST_VALUE()) - Returns the first (or last) value in the input
LEAD() (and LAG()) - Returns the value on a subsequent (or preceding) row
- Analytic numbering functions
Numbering functions assign integer values to each row based on the ordering.
ROW_NUMBER() - Returns the order in which rows appear in the input (starting with 1)
RANK() - All rows with the same value in the ordering column receive the same rank value, where the next row receives a rank value which increments by the number of rows with the previous rank value.
1 | SELECT pickup_community_area, |
HAVING and WHERE
对分组进行筛选.会需要先group by再用having筛选.
1 | SELECT a.title AS Album, COUNT(t.track_number) as Tracks |
where和having的区别.
where用于选行,having用于选组.
where比having先run.
where不可以但having可以加summary function.(where后不可以加单个variable的summary function)
AVG and MIN, MAX and SUM
1 | SELECT COUNT(Population) FROM Country; |
注,sum一定要写在最外面,sum多项时是sum(A,B,C).
sum(A)会从上到下sum A中的所有值.
sum(A,B)会从左到右从上到下sum A B中所有值.
注,语法顺序:
1 | SELECT column1, column2, columnN, sum(columnX) |
所以group by后面接having,where不能用在group by后面.
where:在原表中筛选;having是筛完了后再筛.
SELECT 6
FROM 1
WHERE 2
GROUP BY 3
HAVING 4
ORDER BY 5
Printf
在sqlite里面only.printf(“%X.YF”, expression),第一个%没有意义,X为整数位保留的数据,Y为小数位保留的数据,F为format.
没有四舍五入,是硬截.
1 | printf("%.2f%", (high-low)/(open+close)2100) as vol --123.567 = 123.56(整数位不变,小数位取两位,f为float,最后一个%为加上的char) |
Transaction
可以理解为C语言里的try和catch.如果一个命令fail了,保护其他的/原数据库不会造成影响.
For example:
- A transfer of funds between two accounts should include a debit from one account and a credit to another account in the same amount
- Both actions should succeed or fail together
- The commit should occur after both steps are successfully completed
1 | -- all statement between will be performed by one unit |
1 | BEGIN TRANSACTION; |
Aside: transaction makes things faster also.
Oracle中分为:commit and rollback.有点像git保存,在中间做一个savepoint,可以rollback取消更新.
A database transaction begins when the first DML statement is executed
The transaction ends when one of the following events occurs
- A COMMIT or ROLLBACK statement is issued
- A DDL statement is executed – implicit COMMIT
- A DCL statement is executed – implicit COMMIT
- The user exits SQL Developer
- The database crashes - implicit ROLLBACK
ALL DML CHANGES MUST BE EITHER COMMITED OR ROLLED BACK
Triggers
Will trigger when certain condition meet. Also highly depends on different system.
1 | CREATE TRIGGER newWidgetSale AFTER INSERT ON widgetSale |
we can also use trigger to prevent an update(using rollback).//using before update
1 |
|
and timestamps.
1 | DROP TABLE IF EXISTS widgetSale; |
Exists(Oracle)
- Tests for the existence of a value in the result of the subquery
- If the value is found, the subquery stops and TRUE is returned
- If the value is not found in the subquery, FALSE is returned
- The subquery does not return any table data
- EXISTS was originally introduced to make correlated subqueries more efficient
Who is a manager?
1 | SELECT employee_id, last_name, job_id |
Find departments with no employees, NOT flips TRUE to FALSE
1 | SELECT department_id, department_name |
View
在oracle时的解释:Table: Basic storage unit composed of rows and columns.
View: Shows subsets of data from one or more underlying tables.
- Views control which columns and/or rows a user can see
- Views present a subset of table data to a user
- A view is a SELECT statement that has a name
- Views are permanently stored in the Data Dictionary
Creating a view.
1 | CREATE OR REPLACE VIEW view_name |
Describe the structure of the view
1 | DESC view_name; |
All columns selected in a view must have a name.
1 | CREATE OR REPLACE VIEW yearly_pay_vu |
Modifying a view.
Modify the emps50_vu by reducing the columns selected and giving each column an alias.
1 | CREATE OR REPLACE VIEW emps50_vu (empid, fname, lname, sal, mgr, deptid) |
Dropping a view.
1 | DROP VIEW view_name; |
Schemas
A way to organizing tables and views.
Schemas are grouping structures, we create schema by specifying the create schema command.
Visually it allows us to group things like our tables, views, and indexes into a logical unit.
We could create a schema based on a project or kind of analysis that we’re doing.
1 | CREATE SCHEMA data_sci |
Subselect
把select当作select的source.
1 | SELECT co.Name, ss.CCode FROM ( |
When you SELECT from a subquery, you are selecting from a temporary result set
1 | SELECT AVG(dept_tot) |
- The outer query selects FROM “a”
- a is a query that is inline, has a name, and represents a result set of data, much like a view
- a is known as an Inline View
- An inline view is not permanently stored in the database
Subquery
也就是Nested(嵌套)query.
SQL allows you to embed a query into another query, subquery can be uncorrelated or correlated
Subquery的结构中,整体的叫parent/main query,其中的子query叫nested/inner query.
(当作subset来理解.)
什么时候要使用nested query:无法用and和or做一次查询得出结论,得使用多次查询.(第一次的查询的结果用于第二次查询.)
Uncorrelated subquery:
1 | select distinct card_num from clean_data |
Correlated Subquery:
A sub-query that uses values from the outer query. In this case the inner
query has to be executed for every row of outer query.
1 | select * from disk.multiple_financial as a where exists |
Comparison的时候:
When a subquery might return multiple values, you must use one of the conditional operators ANY or ALL to modify a comparison operator in the WHERE or HAVING clause immediately before the subquery.
For example, the following WHERE clause contains the less than (<) comparison operator and the conditional operator ANY:
1 | where dateofbirth < ANY {subquery...} |
other example:这里的使用是两个select套在一起.查询两个表.
1 | SELECT column1, ... ,columnN |
1 | create table tmp3 as |
注意这里前一个where和后一个select是对应的,不然会出现return和需求的column个数不对.
不一定需要内容一样,但return的column数得相同.
有时可以用join代替,先join再查询.
但建议使用subquery,运算速度会快(提升性能).
在数量对应不上的时候,我们可以用or来拆开子query.
1 | create table tmp9 as |
或者用union合并.
1 | create table tmp10 as |
Subquery(Oracle)
Subquery学的很烂所以在oracle中又记一次.
Subqueries in the where clause
- The inner query executes before the main query.
- The result of the subquery is used to complete the outer query.
- The shorthand shows the basic layout of subqueries in the WHERE
1 | SELECT select_list |
1 | SELECT last_name, salary |
还可以subquery中套outer query.
1 | SELECT column(s) |
Example:
1 | SELECT last_name, salary, job_id |
Single row subqueries
Use single-value comparison operators in the WHERE clause of the outer query
1 | SELECT last_name, job_id, salary |
Multi row subqueries
有IN, ANY, ALL三种.
1 | SELECT last_name, job_id, salary |
1 | SELECT last_name, job_id, salary |
1 | SELECT last_name, job_id, salary |
Subqueries in the having clause
1 | SELECT department_id, MIN(salary) |
(orcacle笔记结束)
With
1 | WITH cte_name AS (SELECT statement) |
Note: WITH clause is mostly equivalent to a subquery.
WITH RECURSIVE is more useful, provide the ability to do hieracrchical/recursive queries
The WITH clause allows complex queries to be broken into smaller blocks.
It is useful when joins, subqueries, aggregation, or repeated query blocks are being used.
WITH allows you to make inline views which can be repeatedly referenced as needed.
The inline views create output that can be used as input to subsequent queries.
Example:
Suppose you need to find the department names and their total salary for any department whose total salary is greater than the average of all the total salaries by department.
Without the WITH clause.
1 | SELECT department_name, SUM(salary) |
The WHERE clause removes employee Grant, with a null department_id, from the calculations.
Using the WITH clause.
1 | WITH a AS ( |
Autoincrement
用于自动添加从1开始的不重复column内容.可以用为增加新的primary key.
1 | create table 'table_name'{ |
但注意,在这样生成的表中.如果一开始的id为1-20.有数据删除再添加,新的数据会从21开始.
Writing Efficient Queries
Avoid scanning too much data at once.
To begin,you can estimate the size of any query before running it.
关于bigQuery这个web service.
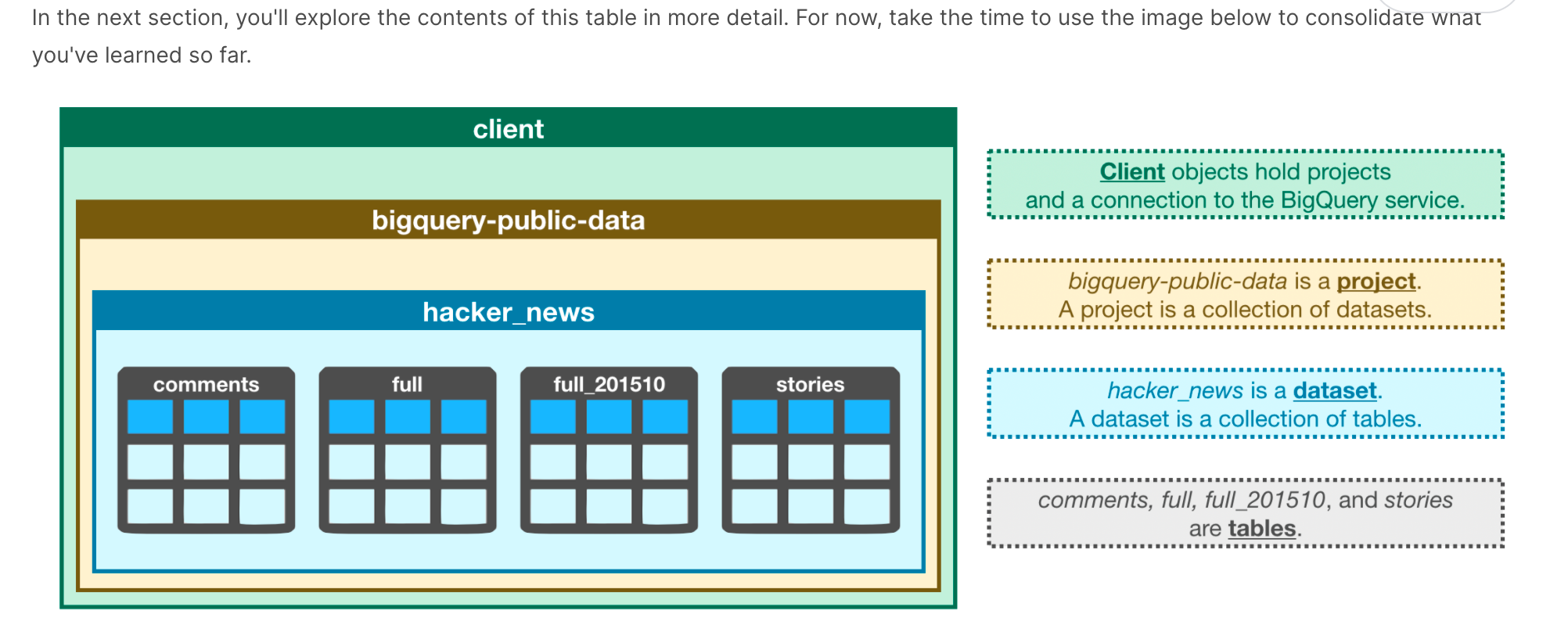
BigQuery里的数据结构.
在bigQuery里可以create a QueryJobConfig object and set the dry_run parameter to True to see how much data a query will scan.
If you are ever unsure what to put inside the COUNT() function, you can do COUNT(1) to count the rows in each group. Most people find it especially readable, because we know it’s not focusing on other columns. It also scans less data than if supplied column names (making it faster and using less of your data access quota).
There are two ways that dates can be stored in BigQuery: as a DATE or as a DATETIME.
The DATE format has the year first, then the month, and then the day. It looks like this:
YYYY-[M]M-[D]D
YYYY: Four-digit year
[M]M: One or two digit month
[D]D: One or two digit day
So 2019-01-10 is interpreted as January 10, 2019.
The DATETIME format is like the date format … but with time added at the end.
There are two ways that dates can be stored in BigQuery: as a DATE or as a DATETIME.
The DATE format has the year first, then the month, and then the day. It looks like this:
YYYY-[M]M-[D]D
YYYY: Four-digit year
[M]M: One or two digit month
[D]D: One or two digit day
So 2019-01-10 is interpreted as January 10, 2019.
The DATETIME format is like the date format … but with time added at the end.
Often you’ll want to look at part of a date, like the year or the day. You can do this with EXTRACT.
1 | WITH LocationsAndOwners AS |
1 | WITH CurrentOwnersCostumes AS |
Why is this better?
Instead of doing large merges and running calculations (like finding the last timestamp) for every costume, we discard the rows for other owners as the first step. So each subsequent step (like calculating the last timestamp) is working with something like 99.999% fewer rows than what was needed in the original query.
Databases have something called “Query Planners” to optimize details of how a query executes even after you write it. Perhaps some query planner would figure out the ability to do this. But the original query as written would be very inefficient on large datasets.