
——
1 - Boxing
值类型与引用类型互相转换:拆箱装箱.
引用类型(Reference types)
引用类型不包含存储在变量中的实际数据,但它们包含对变量的引用。 换句话说,它们指的是一个内存位置。
使用多个变量时,引用类型可以指向一个内存位置。如果内存位置的数据是由一个变量改变的,其他变量会自动反映这种值的变化。
内置的引用类型有:object、dynamic 和 string。
(1)、对象(Object)类型
对象(Object)类型 是 C# 通用类型系统(Common Type System - CTS)中所有数据类型的终极基类。Object 是 System.Object 类的别名。
所以对象(Object)类型可以被分配任何其他类型(值类型、引用类型、预定义类型或用户自定义类型)的值。但是,在分配值之前,需要先进行类型转换。
当一个值类型转换为对象类型时,则被称为 装箱;另一方面,当一个对象类型转换为值类型时,则被称为 拆箱。
(2)、动态(Dynamic)类型
您可以存储任何类型的值在动态数据类型变量中。这些变量的类型检查是在运行时发生的。 声明动态类型的语法:
1 | dynamic <variable_name> = value; |
例如:
1 | dynamic d = 20; |
动态类型与对象类型相似,但是对象类型变量的类型检查是在编译时发生的,而动态类型变量的类型检查是在运行时发生的。
(3)、字符串(String)类型
字符串(String)类型 允许您给变量分配任何字符串值。字符串(String)类型是 System.String 类的别名。它是从对象(Object)类型派生的。字符串(String)类型的值可以通过两种形式进行分配:引号和 @引号。
例如:
1 | String str = "runoob.com"; |
一个 @引号字符串:
1 | @"runoob.com"; |
C# string 字符串的前面可以加 @(称作”逐字字符串”)将转义字符(\)当作普通字符对待,比如:
1 | string str = @"C:\Windows"; |
等价于:
1 | string str = "C:\\Windows"; |
@ 字符串中可以任意换行,换行符及缩进空格都计算在字符串长度之内。
1 | string str = @"<script type=""text/javascript""> |
用户自定义引用类型有:class、interface 或 delegate。我们将在以后的章节中讨论这些类型。
2 - Type
public 全局
protected 子类
internal 同集
private 隐藏
sealed 封闭
Protected: Any field marked with ‘protected’ means it is only visible to itself and any children (classes that inherit from it).
Internal: Accessible within the same assembly but not from another project.
The internal keyword is heavily used when you are building a wrapper over non-managed code.
Sealed: When applied to a class, the sealed modifier prevents other classes from inheriting from it. In the following example, class B inherits from class A, but no class can inherit from class B.
1 | class A {} |
3 - Keywords
Liskov Substitution Principle
Virtual method用于override.拥有virtual method的base class可以单独存在,单独使用.
From 飞哥.
但是简单的讲一下的话,就是说比如说这个A,它这个class它有一个virtual的method叫什么,就是print,然后B呢,它就是inherit a, 然后B它就必须要inherit a的,它这个print method然后也是virtual。
那然后如果我们就我们这个时候如果call就B就是指针嘛,就B的print的话,正常情况下,它这个print是走就是去call b它那个print。就B,the print, the definition, 但是如果你看,因为B它是继承A的嘛,我们可以用A的指针去指B,就一个a star就是指B是可以的,那如果我们用这个指针去call它这个print的话,就是普通就没有virtual的话,他就会跑到A的print那边去。
那有virtual,他就会找啊,原来B他也define了。那我就直接去call B的print。
Abstract跟virtual不一样不能define,abstract class也不能使用.Implement了sub class必须要override abstract class.
Interface不是class,是可以单独存在的blueprint.
有点像unity的UnityEvent.需要对方的object.method.
class.
A structure type (or struct type) is a value type that can encapsulate data and related functionality.
Enum.
We can create a new type with Enum. So for example;
enum color {red, black, orange, blue, yellow}
‘color’ is a type and can be any of the colors we defined (red, black, orange, blue, yellow).
4 - GC Alloc
GC.Alloc means that during the run time your code (or something in the API) allocates this much of the managed memory.
This can cause problems later (that’s why it has the row in the profiler), because when the Garbage Collector runs, it tends to slow down or even hang your game.
It is always a good idea to try to write your game allocation free, which means you avoid APIs and techniques which result in allocation on said managed memory.
- Using a dictionary with an enum will generate garbage, but using a dictionary with int’s won’t, even though you can easily cast between ints and enums
- Debug.Log and prints create garbage (probably the strings)
It’s a huge topic anyways.
CLR: Common Language Runtime, 公共语言运行时,是一种可以支持多种语言的运行时,其基本的核心功能包含:
内存管理
程序集加载和卸载
类型安全
异常处理
线程同步
在CLR中的自动内存管理,就会使用垃圾回收器来执行内存管理,其会定时执行,或者在申请内存分配是发现内存不足时触发执行,也可以手动触发执行(System.GC.Collect)
垃圾回收的几种基本算法
标记清除算法(Mark-Sweep)关键点是,清除后,并不会执行内存的压缩
复制算法(Copying) 内存等额划分,每次执行垃圾回收后,拷贝不被回收的内存到没有被使用的内存块,自带内存压缩,弊端是内存浪费大(每次只能使用部分,预留部分给拷贝使用)
标记整理算法(Mark-Compact)关键点,清除后,会执行内存压缩,不会有内存碎片
分代收集算法(Generational Collection)对内存对象进行分代标记,避免全量垃圾回收带来的性能消耗。下文会详细讲解。
垃圾回收模型
垃圾回收的目的
缘由:内存是有限的,为了避免内存溢出,需要清理无效内存
触发时机
申请分配内存时内存不足(本身不足或者内存碎片过多没有足够大小的内存片)
强制调用System.GC.Collect
CLR卸载应用程序域(AppDomain)
CLR正在关闭(后面2种在进程运行时不会触发)
垃圾回收的流程
GC准备阶段
暂停进程中的所有线程,避免线程在CLR检测根期间访问堆内存.
GC的标记阶段
首先,会默认托管堆上所有的对象都是垃圾(可回收对象),然后开始遍历根对象并构建一个由所有和根对象之间有引用关系的对象构成的对象图,然后GC会挨个遍历根对象和其引用对象,如果根对象没有任何引用对象(null)GC会忽略该根对象。对于含有引用对象的根对象以及其引用对象,GC将其纳入对象图中,如果发现已经处于对象图中,则换一个路径遍历,避免无限循环。
PS:所有的全局和静态对象指针是应用程序的根对象。
垃圾回收阶段
完成遍历操作后,对于没有被纳入对象图中的对象,执行清理操作.
碎片整理阶段
如果垃圾回收算法包含这个阶段,则会对剩下的保留的对象进行一次内存整理,重新归类到堆内存中,相应的引用地址也会对应的整理,避免内存碎片的产生。
5 - 进程(Process)、线程(Thread)和协程(Coroutine)
Difference between concurrency and parallelism.
Coroutines are a form of sequential processing: only one is executing at any given time (just like subroutines AKA procedures AKA functions – they just pass the baton among each other more fluidly).
Threads are (at least conceptually) a form of concurrent processing: multiple threads may be executing at any given time.
6 - Socket通讯
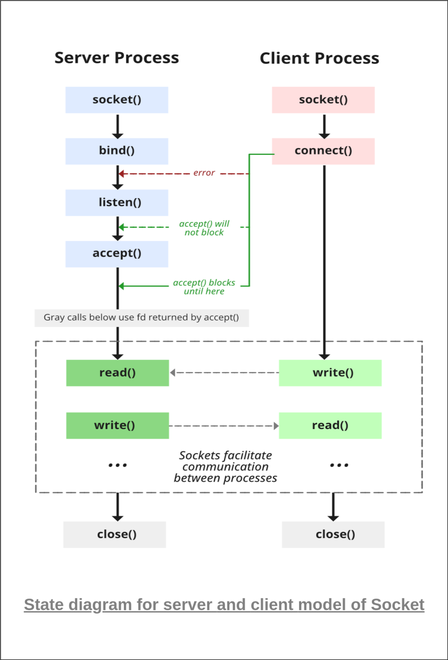
https://stackoverflow.com/questions/4782105/understanding-socket-basics
Http
Let’s take an example when a user sends a request to the server this request goes in the form of HTTP or HTTPS, and after receiving a request server sends the response to the client, each request is associated with a corresponding response, and after sending the response the connection gets closed, each HTTP or HTTPS request establish a new connection to the server every time and after getting the response the connection gets terminated by itself.
WebSocket is a stateful protocol, which means the connection between client and server will stay alive until it gets terminated by either party (client or server).
Socket vs. Websocket
The primary difference between sockets and WebSockets lies in their underlying protocols and communication models. Traditional sockets use protocols like TCP and UDP, where the connection is either connection-oriented (TCP) or connectionless (UDP).
WebSockets, however, operate over the HTTP/1.1 or HTTP/2 protocols, establishing a persistent, bidirectional connection that allows for continuous data exchange without the overhead of repeatedly opening and closing connections.
TCP/IP -> Transmission Control Protocol/Internet Protocol
7 - List
Array in C#
An array is a fixed-size collection of items of the same type.
Arrays are declared using square brackets ([]).
The size of the array is specified when the array is created and cannot be changed afterward.
Arrays provide fast access to elements by their index.ArrayList in C#
An ArrayList is a dynamic-size collection of items of any type.
ArrayLists are declared using the ArrayList class.
The size of the ArrayList can be changed by adding or removing elements.
ArrayLists provide flexibility to add, remove, and modify elements at any position in the List.List in C#
A List is also a dynamic-size collection of items of any type.
Lists are declared using the Listclass, where T is the type of item to be stored.
The size of the List can be changed by adding or removing elements.
Lists provide the same flexibility to add, remove, and modify elements at any position in the List as ArrayLists.
Lists also provide type safety through generics, ensuring that only items of the specified type can be added to the List.
8 - 版本控制与文档管理
“使用版本控制工具(如Git、SVN)进行代码管理,撰写技术文档,确保代码的可维护性和可扩展性.”
9 - What is OOP?
Object-oriented programming (OOP) is a programming paradigm based on the concept of objects, which can contain data and code: data in the form of fields (often known as attributes or properties), and code in the form of procedures (often known as methods).
In OOP, computer programs are designed by making them out of objects that interact with one another.
10 - SDK接入 - software development kit
11 - 六大设计模式
单一职责原则(Single responsibility principle):一个类只做一件事,一个类应该只有一个引起它修改的原因。
A class should have only one reason to change
开闭原则(The Open/Closed Principle):规定“软件中的对象(类,模块,函数等等)应该对于扩展是开放的,但是对于修改是封闭的”,这意味着一个实体是允许在不改变它的源代码的前提下变更它的行为。
Software entities (classes, modules, functions, etc.) should be open for extension, but closed for modification
里氏替换原则(Liskov’s Substitution Principle):子类应该可以完全替换父类。也就是说在使用继承时,只扩展新功能,而不要破坏父类原有的功能。
Derived or child classes must be substitutable for their base or parent classes
接口隔离原则(Interface Segregation Principle):客户端不应依赖它不需要的接口。如果一个接口在实现时,部分方法由于冗余被客户端空实现,则应该将接口拆分,让实现类只需依赖自己需要的接口方法。
do not force any client to implement an interface which is irrelevant to them
依赖倒置原则(Dependency Inversion Principle):细节应该依赖于抽象,抽象不应依赖于细节。把抽象层放在程序设计的高层,并保持稳定,程序的细节变化由低层的实现层来完成。
High-level modules should not depend on low-level modules. Both should depend on abstractions
迪米特法则(The Least Knowledge Principle):又名「最少知道原则」,一个类不应知道自己操作的类的细节,换言之,只和朋友谈话,不和朋友的朋友谈话。
12 - A* search algorithm - 寻路路径
Given a weighted graph, a source node and a goal node, the algorithm finds the shortest path (with respect to the given weights) from source to goal.
G cost -> the distance from the starting node.
H cost(heuristic) -> the distance from the end node.
F cost -> G cost + H cost.
The algorithm compare the lowest F cost in the node and choose it as the path.
Dijkstra’s algorithm (/ˈdaɪkstrəz/ DYKE-strəz) is an algorithm for finding the shortest paths between nodes in a weighted graph, which may represent, for example, a road network.
Dijkstra(戴克斯特拉算法)是本科时学的找short path的方法,放在grid里面过于繁琐.
Dijkstra’s shortest path algorithm is O(ElogV) where:
V is the number of vertices
E is the total number of edges
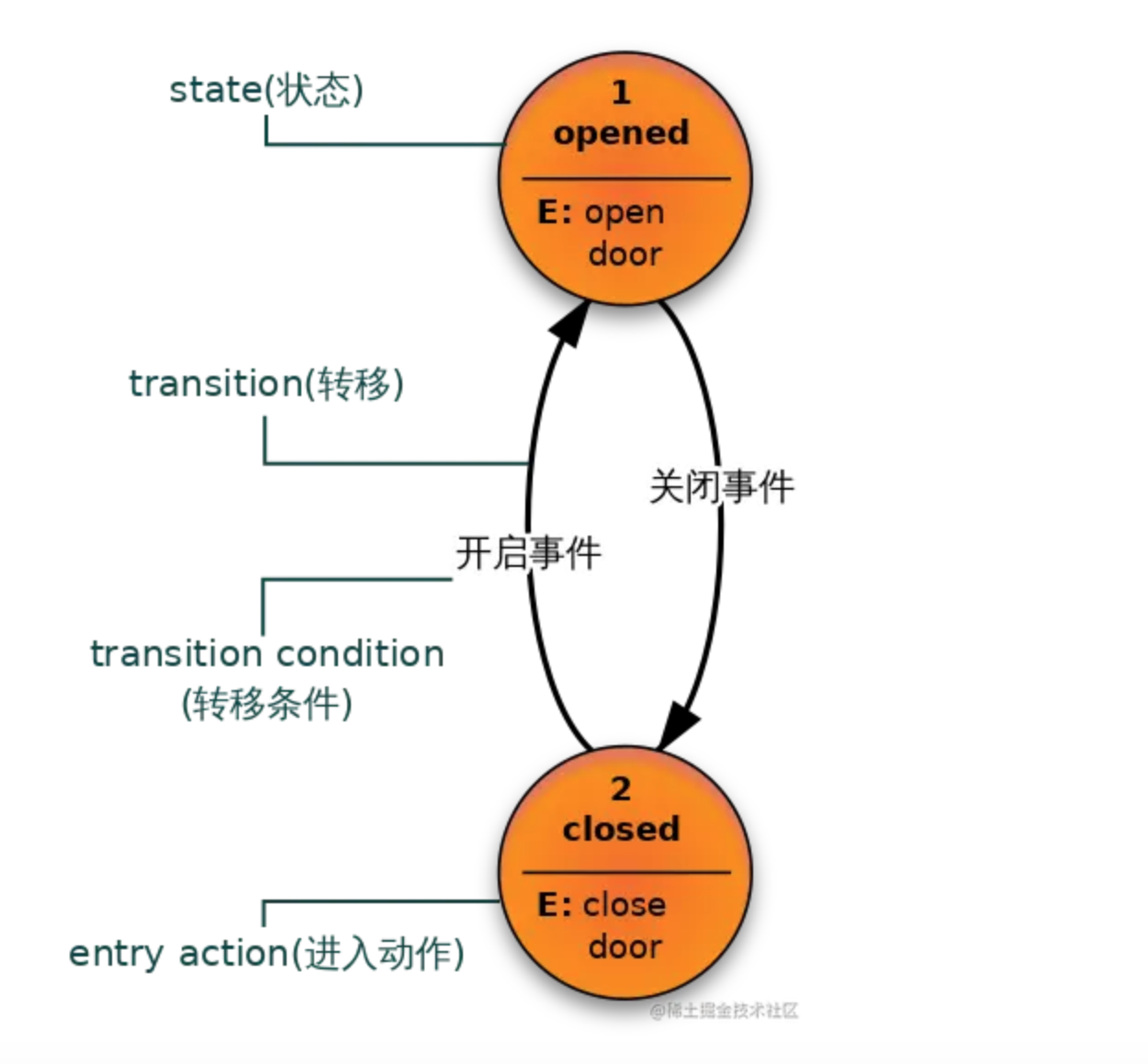
14 - 状态机 - finite-state machine
状态机中有几个术语:state(状态) 、transition(转移) 、action(动作) 、transition condition(转移条件) 。
第一个是 State,状态。一个状态机至少要包含两个状态。例如上面自动门的例子,有 open 和 closed 两个状态。
第二个是 Event ,事件。事件就是执行某个操作的触发条件或者口令。对于自动门,“按下开门按钮”就是一个事件。
第三个是 Action ,动作。事件发生以后要执行动作。例如事件是“按开门按钮”,动作是“开门”。编程的时候,一个 Action 一般就对应一个函数。
第四个是 Transition ,变换。也就是从一个状态变化为另一个状态。例如“开门过程”就是一个变换。
如下图,就定义了一个只有opened和closed两种状态的状态机。当系统处于opened状态,在收到输入“关闭事件”,达到了状态机转移条件,系统就转移到了closed状态,并执行相应的动作,此例有一个进入动作(entry action),进入closed状态,会执行close door动作。
来举个例子。街上的自动售货机中明显能看到状态机逻辑。我们做一下简化,假设这是一台只卖2元一瓶的汽水的售货机,只接受五毛和一块的硬币。初始状态是”未付款“,中间状态有”已付款5毛“,”已付款1块“,”已付款1.5块“,”已足额付款“,四个状态。状态切换的触发条件是”投一块硬币“和”投5毛硬币“两种,”到达足额付款“状态,还要进行余额清零和弹出汽水操作。

图灵机.
15 - Behavior tree (行为树)

行为节点(Action Node)一般分为两种运行状态:
运行中(Executing):该行为还在处理中
完成(Completed):该行为处理完成,成功或者失败
除了行为节点,其余一般称之为控制节点(Control Node).
我们可以为行为树定义各种各样的控制节点(这也是行为树有意思的地方之一),一般来说,常用的控制节点有以下三种
选择(Selector):选择其子节点的某一个执行
序列(Sequence):将其所有子节点依次执行,也就是说当前一个返回“完成”状态后,再运行先一个子节点
顺序(Sequence)结点:按顺序执行孩子结点直到其中一个孩子结点返回失败状态或所有孩子结点返回成功状态。
备选(Fallback)结点:按顺序执行孩子结点直到其中一个孩子结点返回成功状态或所有孩子结点返回失败状态。一般用来实现角色的备选行为。
并行(Parallel):将其所有子节点都运行一遍
并行结点:“并行执行”所有孩子结点。直到至少M个孩子(M的值在1到N之间)结点返回成功状态或所有孩子结点返回失败状态。
而装饰(Decorator)结点只能有一个孩子结点,用来对孩子结点的行为进行自定义修改。
Common policy: invert, repeat/retry, timeout, force failure, success if failure.
我们可以使用装饰器结点(decorator node)来对行为树进行优化。考虑上面的在多个地点搜寻物体的行为树,如果地点数目达到20个以上,整个行为树看上去就会变得非常庞大,也为我们进一步添加新的结点带来麻烦。
下面是避免这些麻烦的常用方法:
引入装饰器结点(decorator node):相较于每增加一个搜寻地点就复制一份完全相同的子树,我们可以定义一个规则为Repeat的装饰器结点,用来重复执行它的孩子结点,完成搜寻多个地点。
在每一次迭代更新目标位置:使用一个队列存储所有待搜寻地点,每次迭代从队列中取出一个地点进行搜寻,当队列为空时,所有地点都被搜寻完毕。
为了存储可以被多个结点访问的共享信息(比如上面提到的存储有所有待搜寻地点的队列),我们引入黑板(blackboard)的概念。黑板是一块可以被结点读写的公共存储区。
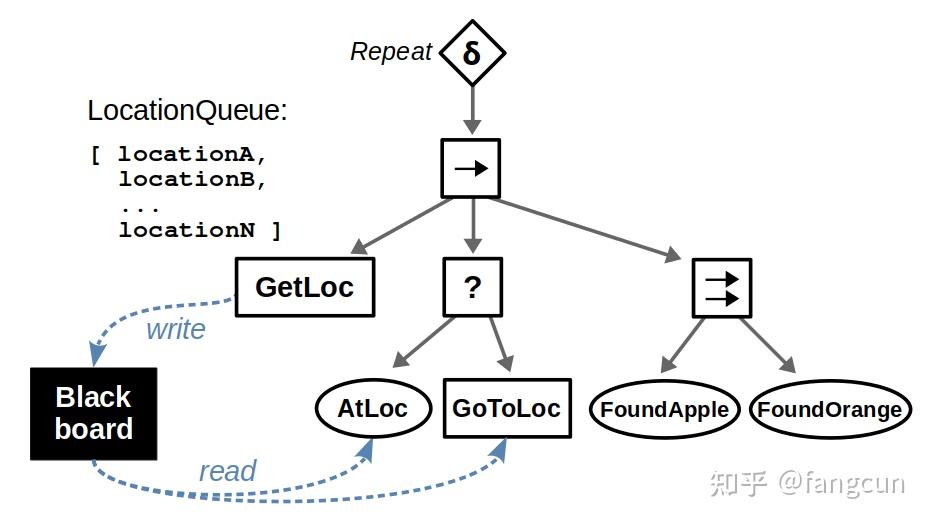
16 - stack and heap
(heap是堆,stack是栈)
stack是一块连续的内存的区域.栈由系统自动分配,速度较快。但程序员是无法控制的.
heap是不连续的内存区域.堆是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便.


17 - 热更新 - 热加载(Hot Loading)
指的是在运行时动态加载和更新软件组件或资源,而无需停止整个应用程序或服务。这种技术允许开发人员在不中断用户体验的情况下,快速地修改和测试代码、样式或配置。
“->用c#需要编译所以比较麻烦”
“用文本文件,SLua,lua,pureTS,是unity热更新的方案”
AssemblyLoadContext
System.Runtime.Loader.AssemblyLoadContext 是 .NET Core 中引入的类,用于加载和管理程序集
在传统的 .NET Framework 中,可以使用 AppDomain 来实现类似的热加载效果。
18 - Unity Input system
19 - ScriptableObject
20 - 红点系统(Reddot System)
21 - QFramework
Others - Questions
- CharacterController和Rigidbody的区别
Rigidbody具有完全真实物理的特性,⽽CharacterController可以说是受限的Rigidbody,具有⼀定的物理效果但不是完全真实的。
是两种不一样的东西.
CharacterController的建造目的是如其名字.
- 当一个细小的高速物体撞向另一个较大的物体时,会出现什么情况?如何避免?
穿透(碰撞检测失败)
- 物理更新一般放在哪个系统函数里?
FixedUpdate,每固定帧绘制时执行一次,和Update不同的是FixedUpdate是渲染帧执行,如果你的渲染效率低下的时候FixedUpdate调用次数就会跟着下降。
FixedUpdate比较适用于物理引擎的计算,因为是跟每帧渲染有关。Update就比较适合做控制。
FixedUpdate,固定时间间隔执行 可以在edit->project setting->time设置 update 是在渲染帧执行
- Image和RawImage的区别
Image比RawImage更消耗性能
Image只能使用Sprite属性的图片,但是RawImage什么样的都可以使用
Image适合放一些有操作的图片,裁剪平铺旋转什么的,针对Image Type属性
RawImage就放单独展示的图片就可以,性能会比Image好很多
The Raw Image can display any Texture whereas an Image component can only show a Sprite Texture.
Note : Keep in mind that using a RawImage creates an extra draw call with each RawImage present, so it’s best to use it only for backgrounds or temporary visible graphics.
- 画布的三种模式.缩放模式
屏幕空间-覆盖模式(Screen Space-Overlay),
Canvas创建出来后,默认就是该模式,该模式和摄像机无关,即使场景内没有摄像机,UI游戏物体照样渲染屏幕空间:电脑或者手机显示屏的2D空间,只有x轴和y轴 覆盖模式:UI元素永远在3D元素的前面
屏幕空间-摄像机模式(Screen Space-Camera),
设置成该模式后需要指定一个摄像机游戏物体,指定后UGUI就会自动出现在该摄像机的“投射范围”内,和NGUI的默认UI Root效果一致,如果隐藏掉摄像机,UGUI当然就无法渲染
世界空间模式(WorldSpace),
设置成该模式后UGUI就相当于是场景内的一个普通的“Cube 游戏模型”,可以在场景内任意的移动UGUI元素的位置,通常用于怪物血条显示和VR开发
- 简述进程(Process)、线程(Thread)和协程(Coroutine)的概念
进程
保存在硬盘上的程序运行以后,会在内存空间里形成一个独立的内存体,这个内存体有自己独立的地址空间,有自己的堆,不同进程间可以进行进程间通信,上级挂靠单位是操作系统。一个应用程序相当于一个进程,操作系统会以进程为单位,分配系统资源(CPU 时间片、内存等资源),进程是资源分配的最小单位。
线程
线程从属于进程,也被称为轻量级进程,是程序的实际执行者。线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条一线程并行执行不同的任务。一个线程只有一个进程。
每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口,但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
线程拥有自己独立的栈和共享的堆,共享堆,不共享栈,线程亦由操作系统调度(标准线程是的)。
协程
协程是伴随着主线程一起运行的一段程序。
协程与协程之间是并行执行,与主线程也是并行执行,同一时间只能执行一个协程提起协程,自然是要想到线程,因为协程的定义就是伴随主线程来运行的。
一个线程可以拥有多个协程,协程不是被操作系统内核所管理,而完全是由程序所控制。
协程和线程一样共享堆,不共享栈,协程由程序员在协程的代码里显示调度。
协成是单线程下由应用程序级别实现的并发。
- 简述协程的作用
在Unity中只有主线程才能访问Unity3D的对象、方法、组件。当主线程在执行一个对资源消耗很大的操作时,在这一帧我们的程序就会出现帧率下降,画面卡顿的现象!
那这个时候我们就可以利用协程来做这件事,因为协程是伴随着主线程运行的,主线程依旧可以丝滑轻松的工作,把脏活累活交给协程处理就好了!简单来说:协程是辅助主线程的操作,避免游戏卡顿。
- 简述协程的底层原理
协程是通过迭代器来实现功能的,通过关键字IEnumerator来定义一个迭代方法。
StartCoroutine 接受到的是一个 IEnumerator,这是个接口,并且是枚举器或迭代器的意思。
yield 是 C#的一个关键字,也是一个语法糖,背后的原理会生成一个类,并且也是一个枚举器,而且不同于 return,yield 可以出现多次。
yield 实际上就是返回一次结果,因为我们要一次一次枚举一个值出来,所以多个 yield 其实是个状态模式,第一个 yield 是状态 1,第二个 yield 是状态 2,每次访问时会基于状态知道当前应该执行哪一个 yield,取得哪一个值。
- 动态加载资源的方式
Instantiate:最简单的一种方式,以实例化的方式动态生成一个物体。
Assetsbundle:即将资源打成 asset bundle 放在服务器或本地磁盘,然后使用www模块get下来,然后从这个bundle中load某个object,unity官方推荐也是绝大多数商业化项目使用的一种方式。
Resource.Load:可以直接load并返回某个类型的Object,前提是要把这个资源放在Resource命名的文件夹下,Unity不管有没有场景引用,都会将其全部打入到安装包中。
AssetDatabase.loadasset:这种方式只在editor范围内有效,游戏运行时没有这个函数,它通常是在开发中调试用的。
- 使用Unity3d实现2d游戏,有几种方式?
1.使用本身的GUI,在Unity4.6以后出现的UGUI
2.把摄像机的Projection(投影)值调为Orthographic(正交投影),不考虑z轴;
3.使用2d插件,如:2DToolKit,和NGUI
- 什么叫做链条关节?
Hinge Joint,可以模拟两个物体间用一根链条连接在一起的情况,能保持两个物体在一个固定距离内部相互移动而不产生作用力,但是达到固定距离后就会产生拉力。
- Unity3d提供了一个用于保存和读取数据的类(PlayerPrefs),请列出保存和读取整形数据的函数
PlayerPrefs.SetInt() PlayerPrefs.GetInt()
- Unity3d脚本从唤醒到销毁有着一套比较完整的生命周期,请列出系统自带的几个重要的方法。
Awake——>OnEnable–>Start——>Update——>FixedUpdate——>LateUpdate——>OnGUI——>OnDisable——>OnDestroy
- 在场景中放置多个Camera并同时处于活动状态会发生什么?
游戏界面可以看到很多摄像机的混合。试一下??
- MipMap是什么,作用?
MipMapping:在三维计算机图形的贴图渲染中有常用的技术,为加快渲染进度和减少图像锯齿,贴图被处理成由一系列被预先计算和优化过的图片组成的文件,这样的贴图被称为MipMap。
- .Net与Mono的关系?
mono是.net的一个开源跨平台工具,就类似java虚拟机,java本身不是跨平台语言,但运行在虚拟机上就能够实现了跨平台。.net只能在windows下运行,mono可以实现跨平台跑,可以运行于linux,Unix,Mac OS等。
- 向量的点乘、叉乘以及归一化的意义?
1.点乘描述了两个向量的相似程度,结果越大两向量越相似,还可表示投影
2.叉乘得到的向量垂直于原来的两个向量
3.标准化向量:用在只关系方向,不关心大小的时候
- 什么是LightMap?
LightMap:就是指在三维软件里实现打好光,然后渲染把场景各表面的光照输出到贴图上,最后又通过引擎贴到场景上,这样就使物体有了光照的感觉。
- uGUI,页面上的一个按钮不能响应点击事件,原因可能有哪些?
- 可能按钮没有link上应该的onClick event
- 有其他的UI部分,比如说图片透明的部分盖住了按钮本身
- EventSytem这个object被不小心删掉了(eventsystem会默认生成,但是比如开新的scene但是复制了按钮没有复制eventsystem那就会出错)
4)按钮的interactable box没有勾上或者是按钮这个component没有勾上(没有active) - 按钮的Y轴反了
- uGUI 中 Mask 和 Rect Mask 2D 的区别是什么?
Mask是对物品的遮挡,rect mask 2D是快捷的矩形状显示,有padding和softness的两大调整功能。Mask可以做矩形以外的物品遮挡。Mask需要创造image的子组件来划出遮挡区域。
- Unity 中有哪些方式可以实现异步操作,分别给出优缺点。
1) Coroutine
格式为
1 | // inside of the function |
在iEnumerator中没法return一个值。
当使用coroutine的时候,如果附带代码的object被destory或者inactive了,coroutine中的代码不会执行。
- Async and Await and Task
1 | async void theFunction(){ |
当使用coroutine的时候,如果附带代码的object被destory或者inactive,async和await可以执行代码,也可以return一个值。Awaitablede的任务会拍成池子放到limit allocations里面。
但是任务会把本身正在运行的主线程停住,如果有两个任务互相等待,就会被堵住。
- 从渲染的角度,简要描述一下从加载模型,到屏幕中显示模型中间经历了哪些步骤。
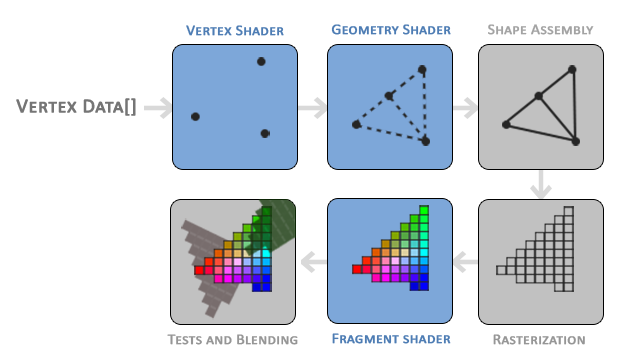
Note that the blue sections represent sections where we can inject our own shaders.
顶点着色器的核心功能就是完成将3维坐标中的点,通过变换和投影,转换为2维的屏幕上。
作为渲染管线的开端,顶点着色器不止承担着接收顶点的任务,作为一段拥有具体逻辑的应用程序,它还承受着处理顶点位置以便完成一些效果等任务(比如位置变换、调整形状,或者三维变换),另外还起着传输各种从客户端程序传入的各种数据(比如颜色、变换矩阵、时间参数等)并将数据传递给后面阶段的任务。
https://juejin.cn/post/7134356782452834334
ApplicationStage:准备场景信息,定义模型的渲染命令(材质,shader)
GemetryStage:顶点着色器,曲面细分着色器,几何着色器,裁剪,屏幕映射
RasterizerStage:三角形设置,三角形设置遍历,片元着色器,逐片元操作
1 | Shader "Unlit/NewUnlitShader" |
Each SubShader is composed of a number of passes, and each Pass represents an execution of the vertex and fragment code for the same object rendered with the material of the shader.
Many simple shaders use just one pass, but shaders that interact with lighting might need more (see Lighting Pipeline for details).
Commands inside Pass typically setup fixed function state, for example blending modes.
GPU工作流程:顶点处理、光栅化、纹理贴图、像素处理
顶点处理:这阶段GPU读取描述3D图形外观的顶点数 据并根据顶点数据确定3D图形的形状及位置关系,建⽴起3D图形的⻣架。
光栅化:把⼀个⽮ᰁ图形转换为 ⼀系列像素点的过程就称为光栅化
纹理贴图:就是将多边形的表⾯贴 上相应的图⽚,从⽽⽣成“真实”的图形。
像素处理:这阶段(在对每个像素进⾏光栅化处理期 间)GPU完成对像素的计算和处理,从⽽确定每个像素的最终属性。
最终输出:由ROP(光栅化引擎)最终完成像素的输 出,1帧渲染完毕后,被送到显存帧缓冲区。
————————————————
- localPosition 与 Position 的使用区别?
localPosition :自身坐标系,相对于父级的位置
Position :世界坐标系中的位置
- Unity3D Shader分哪几种,有什么区别?
表面着色器的抽象层次比较高,它可以轻松地以简洁方式实现复杂着色。表面着色器可同时在前向渲染及延迟渲染模式下正常工作。
顶点片段着色器可以非常灵活地实现需要的效果,但是需要编写更多的代码,并且很难与Unity的渲染管线完美集成。
固定功能管线着色器可以作为前两种着色器的备用选择,当硬件无法运行那些酷炫Shader的时,还可以通过固定功能管线着色器来绘制出一些基本的内容。
Before going into the whole chain, I’m going to talk about what a draw call is. A draw call is something the CPU does when it tells the GPU it should render. It’s big and scary; it’s the thing all the young game devs talk about when they tell their tales of trying to get their game to run fast!
An actual draw call looks something like this:
context->Draw(24, 0);
That’s it. That draws a cube, with a specific shader, and has all the other important data needed to put that object on screen. No really. When the GPU receives that, it immediately starts rendering a cube, or at least as soon as it’s not doing anything else.
But how? There are just two numbers there, that couldn’t possibly be enough information! Yep, it’s not. That’s because the draw call by itself is really just saying “okay, now draw with all the information I’ve previously setup”.
Okay, let’s start at the beginning again. This won’t be exactly how Unity does things, but it’ll be a little more accurate than what your rundown was.
You’ve got a single camera scene of several cubes, all the same mesh, but using a mix of different shaders and textures. Let’s render the first frame.
CPU:
Renderers: Unity goes through the scene’s renderer components and adds them to a list.
Culling: Unity does a pass at culling the renderers. Each mesh has a bounding box, that’s converted into an AABB per renderer, and Unity checks those against the frustum of the camera. Any renderers who’s bounds that aren’t visible are skipped and removed from the lists. It also compares the layer mask on the camera against the renderer’s game object and skips those that aren’t visible.
Gather Asset Data: Unity gets a list of all meshes, textures, and shaders that the remaining renderer components are referencing. Note, I’m not mentioning materials here, but those are really just ways to reference textures, shaders, and a list of extra variables.
Upload Asset Data: Unity checks if this is the first time any of them have been seen, and if so it uploads them to the GPU. In the case of the textures, it uploads the texture data and gets a handle to that texture. It then does the same for the two shaders, and the mesh data. The mesh data is actually multiple chunks of data. For a cube, that’s a struct array of data for each of the 24 vertices (position, UVs, color, etc), and an index array which would be 36 ints that index those 24 vertices, 3 for each triangle with some triangles sharing vertices. For a lot of this data, once it’s uploaded to the GPU, it’s deleted from the CPU memory.
Sorting: Next Unity is going to sort off of the renderer components. There’s several parts to this, render queue, materials, lighting, distance, etc. We’ll ignore most of those and just focus on distance, or “depth” sorting and transparent vs opaque sorting and say all materials are using one of those two queues. Opaque objects get put into one pile, then sorted front to back. That is the objects closer to the camera (based on a sphere that encapsulates the AABB) get sorted to the top of the list. Transparent objects get put into the other pile and sorted back to front; further away objects are sorted to the top of that list.
Setup Rendering: Here’s where the real meat begins. Unity already uploaded the asset data to the GPU, and has handles to them rather than direct references. So to draw something it just needs to say “hey, we want to use this asset now”. But before that we also need to setup some other data that isn’t going to change between objects. Mainly stuff like the camera’s world to view transform and projection matrices. Those will get shared by everything so that gets setup once and sent to the GPU. This also tells the GPU to set up the render target / frame buffer, or clear it from the previous frame.
Render Object: After the shared data is setup we tell the GPU the per object data for the first object on the list: It’s object to world transform matrix, any float / vector / color parameters the material had, what textures it needs and on which inputs, and what mesh asset to use. It also tells the GPU which shader to use, and sets up the effect state. Things like the blend mode, front or back face culling, ZTest, ZWrite, etc. Then it says “draw that”. Any values that don’t change from the previously rendered object are left alone and don’t need to be sent again.
Opaques: Repeat step 7 until we’re out of stuff in the opaque list.
Skybox: At this point Unity renders the skybox mesh with a special transform matrix so that it is effectively infinitely far away. Really this is no different than step 7, it just isn’t a “renderer” component.
Transparencies: Repeat step 7 again, but for all of the transparent list.
Tell the GPU we’re done, and display the results.
And we’re done, Repeat 1 through 11 for the next frame. At least we’re done for the CPU.
GPU:
Assets: During step 4 of the CPU side, the GPU took the data uploaded to it and put it into it’s memory. That’s it. Technically the handle was returned by the CPU side graphics APIs, which got them from the CPU side graphics drivers, which told the GPU “here’s some data, put it at this memory address”. The GPU just took the data and responded with “ah-yup!”
Mutable Data: During CPU step 6, basically the same thing as GPU step 1 happens. “Ah-yup”. Same with CPU step 7, with some additional switches being flipped and instructions being handed out. Get some memory space ready to render into.
Draw Call: And then it begins. We draw one cube.
Vertex Shader: The GPU has multiple cores, somewhere between several tens to many thousands. In most modern GPUs these are general purpose, at least in terms of the kind of code that GPUs can run. So for something like a cube with only 24 vertices, all of these will get processed in parallel. Each vertex position is transformed from the “local” space (the data that’s stored in the GPU’s vertex data struct array) to homogeneous clip space. It also optionally modified or passes on any extra data, like the UVs and color, if the shader has code for that, as well as take and process any other material properties it might need for this stage.
Rasterization: Next the GPU goes through the index array and calculates the screen coverage for each triangle based on the vertex positions. This is done in the order they exist in the array and not in parallel. If a triangle doesn’t cover any pixels on screen, it is skipped. If it has ZTest it’ll test against the depth buffer and skip pixels that aren’t visible. If ZWrite is on, it’ll update the depth buffer with the new depth. Then it’ll start drawing the pixels for that triangle. For each pixel it needs to calculate the barycentric coordinate, and interpolate the vertex data to pass on to that pixel’s fragment shader.
Fragment Shader: Pixels on screen are processed in batches. At the smallest, this is in groups of 2x2 pixels calculated in parallel. But that may also be as part of larger batches of 8x8 pixels or 16x8 pixels or other size groups. The pixels in each batch all run in parallel, per triangle. If a single pixel is visible in one of these larger groups, the other cores may be completely idle, or calculating values for pixels outside the triangle’s coverage or otherwise hidden. The fragment shader takes the interpolated data for its position, as well as any of the material properties and a texture data, and puts it together to form a single color value. Textures are sampled with specialized hardware that handles fast decoding of the various texture formats and filtering and splits out a color value for the shader to use.
ROP: The values output by the fragment shader are blended into the frame buffer. For opaques, this is usually just a replacement of the current color value. For transparent objects this may be alpha blending or additive blending. The GPU has specialized hardware that handles this.
Repeat all parts of step 3 for every draw call, in the order the CPU sent them.
Send the final image in the frame buffer to the monitor.
Then the next frame starts and we do it all over. Note that all that texture, shader, and mesh data just sits there on the GPU and gets reused over and over. I’m skipping a bunch of things in there too, but that’s the gist.
Fundamentally a UV is a 2D position within a texture
letters U (Horizontal) and V (Vertical)
UV is a texture coordinate in 2D form that corresponds to an object in 3D form
The term UV mapping originates from the coordinate system used to apply 2D textures onto 3D models.
Input a custom vertex structure
To access different vertex data, you need to declare the vertex structure yourself, or add input parameters to the vertex shader. Vertex data is identified by Cg/HLSL semantics, and must be from the following list:
POSITION is the vertex position, typically a float3 or float4.
NORMAL is the vertex normal, typically a float3.
TEXCOORD0 is the first UV coordinate, typically float2, float3 or float4.
TEXCOORD1, TEXCOORD2 and TEXCOORD3 are the 2nd, 3rd and 4th UV coordinates, respectively.
TANGENT is the tangent vector (used for normal mapping), typically a float4.
COLOR is the per-vertex color, typically a float4.
https://developer.unity.cn/projects/665a7cc9edbc2a001dac7033
https://blog.csdn.net/qq_21407523/article/details/108814300
https://github.com/Lafree317/Unity-InterviewQuestion/blob/master/README.md
Parsec.
Parsec is a proprietary remote desktop application primarily used for playing games through video streaming.
https://unity.com/resources/user-interface-design-and-implementation-in-unity