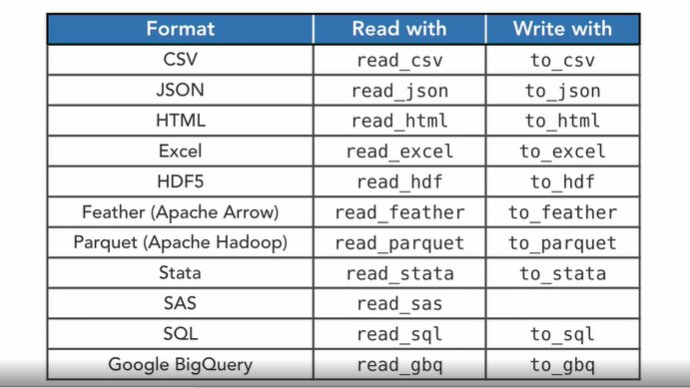
联动第一季.
来源Linkedin learning.
这里包括了一些python和numpy的review.
shift + enter -> run the block of code
用tab老样子跳到下一个block
Python
List
Python list can be negative
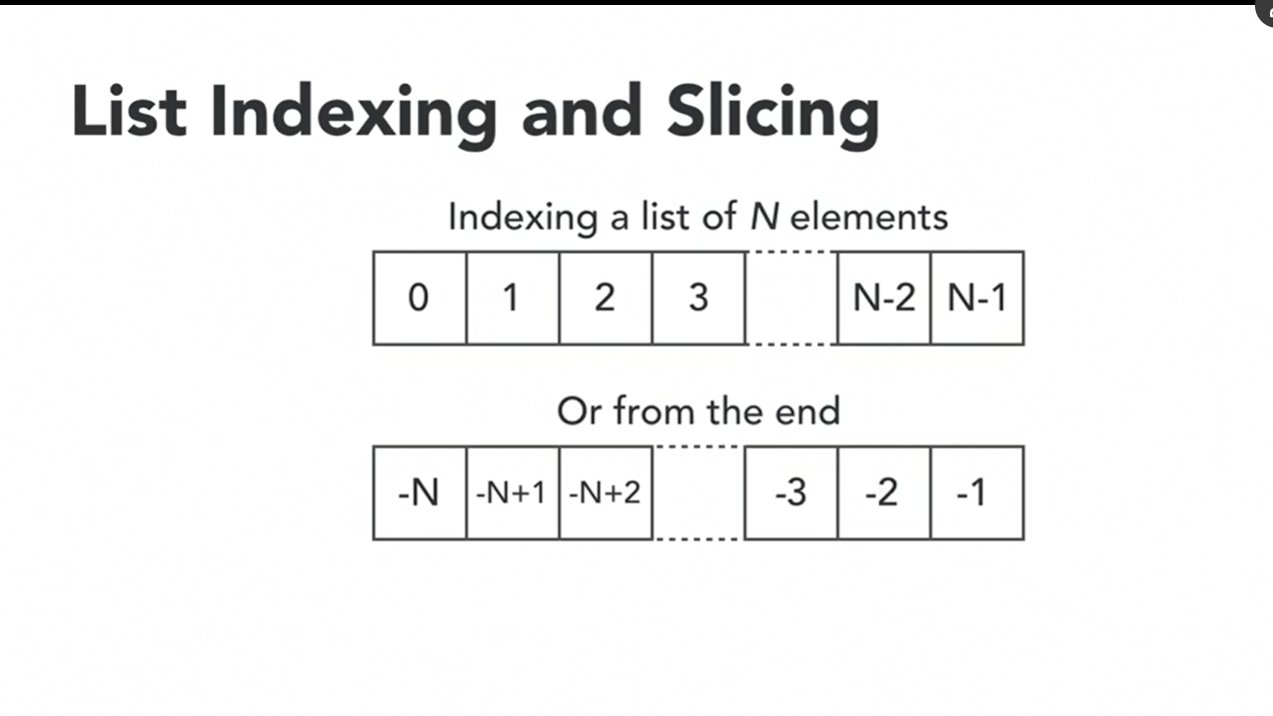
原来负数的index是这个意思!
Python list can be mixed with numbers and strings
1 | nephews = ["Huey", "Dewey", "Louie"] |
Append:
1 | nephews.append('April Duck') |
都可以append.
Insert:
1 | # insert into any position |
Delete:
1 | # with position |
Sort:Python自带sort,隔壁的c羡慕的留下了口水.
1 | ducks.sort() |
Tuples
Looks like list but use parentheses instead of brackets.
1 | integers = ('one', 'two', 'three', 'four') |
We can use index to read element and slicing tuples, but we can not modify the elements or add new ones.
‘tuple’ object does not support item assignment
一个特殊用法:可以用tuple打包给function数据.
1 | def three_args(a, b, c): |
Function takes tuple with prefix asterisk.
注意啊这里,tuple是有多个arguement的.要把tuple分开来送给function,unpack tuple,要使用*.
Dictionary
1 | capitals = {'United States': 'Washington, DC', 'France': 'Paris', 'Italy': 'Rome'} |
Here countries are keys in the dictionary.
1 | # all items in the Italy |
Access a nonexistent item results a key error.
but if we do
1 | capitals['Spain'] = 'Madrid' |
We will add an item, if spain not exist.
1 | 'Germany' in capitals, 'Italy' in capitals |
This can check whether or not item is in the dictionary.
To combine two dictionary.
1 | morecapitals = {'Germany': 'Berlin', 'United Kingdom': 'London'} |
We need to use update, in order to prevent duplicate key error.
Delete.
1 | del capitals['United Kingdom'] |
Key does not need to be a string, any python object that is hashable may be used as a name.
Hashable here meaning python can convert it to a number.
Looping in dictionary:
1 | # default keys |
Sets
Bags of item, can be mixed types and do not have duplicate.
1 | continents = {'America', 'Europe', 'Asia', 'Oceania', 'Africa', 'Africa'} |
1 | # check existent |
Comprehensions
Compress version of loop.
正常:
1 | squares = [] |
Comprehension:
1 | # list of the squares from 1^2 to 10^2; note power is ** in Python |
Collection
1 | # defining the namedtuple "person" |
Nametuple is to create a specialized object(tuple) that has a name and associate labels with fields.
1 | # creating instances using persontype |
Access to the field.
1 | michele[0], michele[1], michele[2] |
Anagram
这是个例题不是python的语法,但是挺好玩的所以记载下.
题目是导入字典里的文字,寻找其中anagram(相同字母)的单词.
思路是把每个单词分成字母组来比对.
1 | # iterating over an open file yields its lines, one by one |
1 | words[:10] |
查看单词的时候发现读入时加入了\n,于是手动去除一下.
1 | 'Aaron\n'.strip().lower() |
像这样.
1 | words = [] |
注意set是不包括重复元素的.
用这个特性给每个单词存在set中.
1 | words = [] |
1 | # 这里排序了存储 |
特性之,把字母拆成char排序后,用同样的字母的单词可以对的上.
1 | sorted("elvis") == sorted("lives") |
会return true.
1 | # compute the signature string for a word |
Signature的意义比如”aaron”这个词,会被排序成’aanor’,这是每个词的signature.
这里words_by_sig就把每个词的anagram找好了:
‘a’: {‘a’},
‘aa’: {‘aa’},
‘aal’: {‘aal’, ‘ala’}
除去每个词自身.
1
2
3
4# keep only the key/value pairs where the set has more than one element;
# this is now a regular dict
anagrams_by_sig = {sig: wordset for sig, wordset in words_by_sig.items() if len(wordset) > 1}
‘aal’: {‘aal’, ‘ala’},
‘aam’: {‘aam’, ‘ama’},
‘aacinor’: {‘aaronic’, ‘nicarao’, ‘ocarina’}
1 | # handle case when myword's signature is not found, returning the empty set |
NumPy
Python variables are often described as labels. They are not little boxes in computer memory ready to receive a value. Rather the values are independent objects with their own space in memory and Python variables are labels or names that are attached to the values. So you can have more than one variable referring to the same object.
也就是python万物pointer说.
NumPy array can reserve space in memory and store all values side by side.
All data in an array need to have the same size.
也就是C里的array.
NumPy数据类:
- Integers: numpy.int8, numpy.int16, numpy.int32, numpy.int64
- Unsigned integers: numpy.unit8 and so on
- Floating-point numbers: numpy.float32, numpy.float64, numpy.float128
- Complex: numpy.complex64 and so on
- Others: bool, str(fixed length), numpy.void(record arrays), and object(reference)
NumPy array读自文件:
1 | monalisa_bw = np.loadtxt('monalisa.txt') |
文件是一行一行带空格的数据.
107 93 104 83 91 66 70 77 62 91 89 74 90 68 65 101 93 74 68 77 73 75 77 85 77 71 82 80 74 69 56 50 53 74 63 54 63 88 103 74 67 73 85 72 75 81 107 69 63 73 72 90 89 97 78 74 92 83 92 85 93 92 66 79 73 77 85 100 83 86 84 80 74 78 86 77 66 68 65 68 63 71 90 76 67 50 37 41 51 46 61 82 61 62 58 79 60 49 59 59 70 69 72 67 95 77 70 72 70 65 91 70 64 78 74 61 56 75 51 59 100 95 65 46 49 75 65 91 85 87 88 87 78 95
72 96 99 93 84 85 80 84 96 95 82 85 89 94 82 65 74 90 62 85 75 88 71 77 101 83 100 59 68 73 68 80 89 84 89 82 55 82 96 88 80 93 92 76 87 83 84 70 76 76 79 96 91 125 93 94 98 104 83 86 102 70 88 95 88 110 90 94 76 85 88 74 65 85 85 85 79 90 82 101 87 89 84 98 94 91 83 67 72 86 78 73 74 73 85 82 71 76 60 78 68 68 82 61 55 60 68 78 74 91 92 87 73 78 50 85 76 73 76 67 76 73 74 83 77 77 80 94 80 64 76 68 95 73
所以被分成了2D array.
Check dimension.
1 | monalisa_bw.ndim |
Rows and columns.
1 | monalisa_bw.shape |
Data types.
1 | monalisa_bw.dtype |
NumPy 创造array:
1 | zero_1d = np.zeros(8, 'd') # d short for np.float64 |
1 | # 可以做一个同样size的值为0的array |
Save file.
1 | np.save('random.npy', rand_2d) |
这里比较有意思的是,因为文件是monalisa的pixel info.
所以类似也可以用random的function打马赛克.
1 | np.random.randint(100,255,size=(280,280,3)) |
Pandas