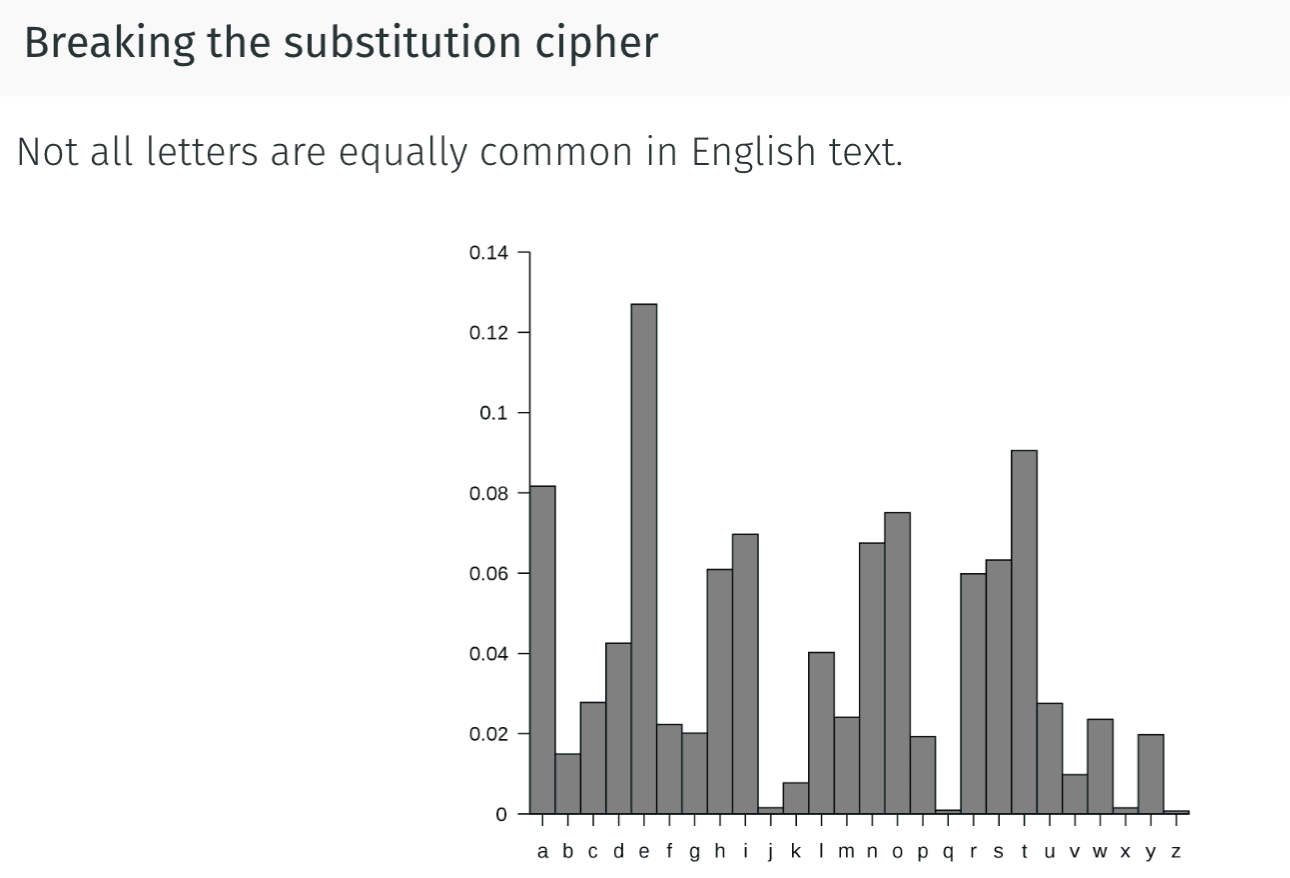
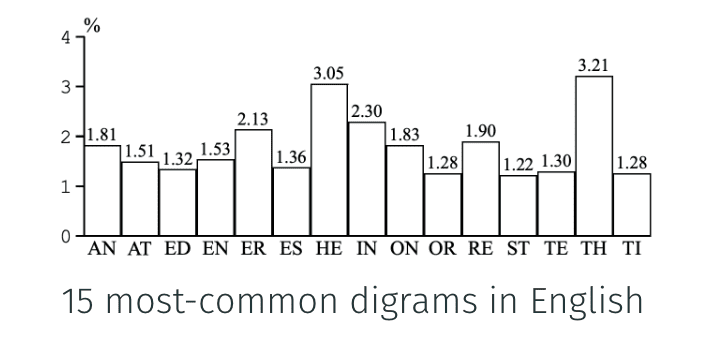
中文维基翻译是流密码,是一种对称加密算法.
起因是这样,这个学期我回去重上co487,密码学.上次drop的原因是期中考撞上疫情爆发,我也没学好,手忙脚乱的炸掉两门期中,就干脆二进宫了.
三种是
Random simple substitution cipher
Vigenere cipher
Transposition cipher
Substitution cipher 维基介绍:
簡易替換加密是一種以特定方式改變字母表上字母順序,並以此順序書寫的加密方式。這樣一張改變了字母次序的字母表即為『替換表』。
例子
明文為 ABCDEFGHIJKLMNOPQRSTUVWXYZ
flee at once. we are discovered!
SIAA ZQ LKBA. VA ZOA RFPBLUAOAR!
Vigenere cipher 维基介绍:
在一个凱撒密碼中,字母表中的每一字母都会作一定的偏移,例如偏移量为3时,A就转换为了D、B转换为了E……而维吉尼亚密码则是由一些偏移量不同的恺撒密码组成。
例如,假设明文为:
ATTACKATDAWN
选择某一关键词并重复而得到密钥,如关键词为LEMON时,密钥为:
LEMONLEMONLE
对于明文的第一个字母A,对应密钥的第一个字母L,于是使用表格中L行字母表进行加密,得到密文第一个字母L。类似地,明文第二个字母为T,在表格中使用对应的E行进行加密,得到密文第二个字母X。以此类推,可以得到:
明文:ATTACKATDAWN
解密的过程则与加密相反。例如:根据密钥第一个字母L所对应的L行字母表,发现密文第一个字母L位于A列,因而明文第一个字母为A。密钥第二个字母E对应E行字母表,而密文第二个字母X位于此行T列,因而明文第二个字母为T。以此类推便可得到明文。
C_i = P_i + K_i (mod 26)
解密方法则能写成:
P_i = C_i - K_i (mod 26)
Transposition cipher 维基…没有中文介绍!!
For example, suppose we use the keyword ZEBRAS and the message WE ARE DISCOVERED. FLEE AT ONCE. In a regular columnar transposition, we write this into the grid as follows:
6 3 2 4 1 5
比如说这里是第一列换到第六列的位置,第二列换到第三列的位置,以此类推.为使满足n*6的字母数,多加了5个随机的字母.
providing five nulls (QKJEU), these letters can be randomly selected as they just fill out the incomplete columns and are not part of the message. The ciphertext is then read off as:
EVLNE ACDTK ESEAQ ROFOJ DEECU WIREE
以上就是作业中出现的三种加密方式.
每两个字母的组合也有不同的频率.
在这个情况下分析三种加密方式,通过三种的加密文有/没有这两种频率倾向来猜测加密种类.
首先是cryptool.
https://www.cryptool.org/en/
这是款很老很老的软件但是很厉害,它里面包括了很多常见的加密方法,可以输入key来加密/解密.
https://crypto.interactive-maths.com/frequency-analysis-breaking-the-code.html
https://tholman.com/other/transposition/
输入排列时每组的长度,然后直接根据拖动来调整字母位置,导出明文/密文.这个也相当好玩……
最后是小代码 使用语言C++14.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 #include <iostream> #include <map> #include <string> #include <fstream> #include <cstdlib> using namespace std;int main (int argc, const char * argv[]) cout << "Instruction in case I forgot!" << endl; cout << endl; cout << "include a file call names.txt to include the words wanna count" << endl; cout << "if you go with ./a.out -n that means add a skip space that counting char" << endl; cout << "by default we count one char by one char" << endl; cout << "for example we input 2 by count [abc], then only a and c will be counted" << endl; cout << "also add a space that we start to counting on" << endl; cout << "we suggest this num should smaller than skip(or at least smaller than your file length)" << endl; cout << endl; int theArray[26 ]; for (int i = 0 ; i < 26 ; i++) { theArray[i] = 0 ; } int skip = 1 ; int ignore = 0 ; int index = 0 ; if ( argc > 1 ){ for (int i = 1 ; i < argc ; i++){ if (argv[i][0 ] == '-' ){ if (argv[i][1 ] == 'n' ){ cout << "add the num space you wanna skip " << endl; string tempNum; cin >> tempNum; skip = stoi (tempNum); cout << "skip :" << skip << endl; cout << "add the num you wanna ignore in the front " << endl; cin >> tempNum; ignore = stoi (tempNum); cout << "ignore :" << ignore << endl; } } } } ifstream file{"names.txt" }; string s; int countRound = 0 ; while (file >> s){ string tb = s; int tempStrLength = s.length (); char w[tempStrLength + 1 ]; strcpy (w, s.c_str ()); for (int j = 0 ; j < tempStrLength; j = j + 1 ) { if (ignore == 0 ){ if (countRound == 0 ){ switch (w[j]) { case 'a' : theArray[0 ]++; break ; case 'A' : theArray[0 ]++; break ; case 'b' : theArray[1 ]++; break ; case 'B' : theArray[1 ]++; break ; case 'c' : theArray[2 ]++; break ; case 'C' : theArray[2 ]++; break ; case 'd' : theArray[3 ]++; break ; case 'D' : theArray[3 ]++; break ; case 'e' : theArray[4 ]++; break ; case 'E' : theArray[4 ]++; break ; case 'f' : theArray[5 ]++; break ; case 'F' : theArray[5 ]++; break ; case 'g' : theArray[6 ]++; break ; case 'G' : theArray[6 ]++; break ; case 'h' : theArray[7 ]++; break ; case 'H' : theArray[7 ]++; break ; case 'i' : theArray[8 ]++; break ; case 'I' : theArray[8 ]++; break ; case 'j' : theArray[9 ]++; break ; case 'J' : theArray[9 ]++; break ; case 'k' : theArray[10 ]++; break ; case 'K' : theArray[10 ]++; break ; case 'l' : theArray[11 ]++; break ; case 'L' : theArray[11 ]++; break ; case 'm' : theArray[12 ]++; break ; case 'M' : theArray[12 ]++; break ; case 'n' : theArray[13 ]++; break ; case 'N' : theArray[13 ]++; break ; case 'o' : theArray[14 ]++; break ; case 'O' : theArray[14 ]++; break ; case 'p' : theArray[15 ]++; break ; case 'P' : theArray[15 ]++; break ; case 'q' : theArray[16 ]++; break ; case 'Q' : theArray[16 ]++; break ; case 'r' : theArray[17 ]++; break ; case 'R' : theArray[17 ]++; break ; case 's' : theArray[18 ]++; break ; case 'S' : theArray[18 ]++; break ; case 't' : theArray[19 ]++; break ; case 'T' : theArray[19 ]++; break ; case 'u' : theArray[20 ]++; break ; case 'U' : theArray[20 ]++; break ; case 'v' : theArray[21 ]++; break ; case 'V' : theArray[21 ]++; break ; case 'w' : theArray[22 ]++; break ; case 'W' : theArray[22 ]++; break ; case 'x' : theArray[23 ]++; break ; case 'X' : theArray[23 ]++; break ; case 'y' : theArray[24 ]++; break ; case 'Y' : theArray[24 ]++; break ; case 'z' : theArray[25 ]++; break ; case 'Z' : theArray[25 ]++; break ; default : break ; } } countRound = countRound + 1 ; if (countRound == skip){ countRound = countRound - skip; } }else { ignore = ignore - 1 ; } index++; } } cout << "a num: " << theArray[0 ] << endl; cout << "b num: " << theArray[1 ] << endl; cout << "c num: " << theArray[2 ] << endl; cout << "d num: " << theArray[3 ] << endl; cout << "e num: " << theArray[4 ] << endl; cout << "f num: " << theArray[5 ] << endl; cout << "g num: " << theArray[6 ] << endl; cout << "h num: " << theArray[7 ] << endl; cout << "i num: " << theArray[8 ] << endl; cout << "j num: " << theArray[9 ] << endl; cout << "k num: " << theArray[10 ] << endl; cout << "l num: " << theArray[11 ] << endl; cout << "m num: " << theArray[12 ] << endl; cout << "n num: " << theArray[13 ] << endl; cout << "o num: " << theArray[14 ] << endl; cout << "p num: " << theArray[15 ] << endl; cout << "q num: " << theArray[16 ] << endl; cout << "r num: " << theArray[17 ] << endl; cout << "s num: " << theArray[18 ] << endl; cout << "t num: " << theArray[19 ] << endl; cout << "u num: " << theArray[20 ] << endl; cout << "v num: " << theArray[21 ] << endl; cout << "w num: " << theArray[22 ] << endl; cout << "x num: " << theArray[23 ] << endl; cout << "y num: " << theArray[24 ] << endl; cout << "z num: " << theArray[25 ] << endl; cerr << endl; }